AI Integration · Machine Learning
Small Language Models in Production: Deploying Phi-4, Qwen, and Gemma at the Edge
A practical guide to deploying Small Language Models (SLMs) like Phi-4, Qwen2.5, Gemma 3, and Llama 3.2 in production. Benchmarks, quantization, edge deployment patterns, and when SLMs beat large models.

Anurag Verma
15 min read

Sponsored
I used to spin up a GPT-4 API call for everything. Summarize a support ticket? GPT-4. Extract structured data from a receipt? GPT-4. Classify user intent in a chatbot? You guessed it — GPT-4. Our monthly API bill looked like a car payment, latency was measured in full seconds, and every request shipped user data to a third-party server.
Then I discovered small language models, and I have not looked back.
Over the past year, our team at CoderCops has deployed Phi-4, Qwen2.5, Gemma 3, and Llama 3.2 small variants across mobile apps, IoT gateways, browser extensions, and edge servers. The results have been genuinely surprising: for the vast majority of production tasks, a well-tuned 3B parameter model running locally obliterates a 200B+ cloud model on the metrics that actually matter — latency, cost, and privacy.
This post is the guide I wish I had when we started. Benchmarks, deployment patterns, quantization tricks, and the honest trade-offs.
What Counts as a “Small” Language Model in 2026?
The industry has loosely settled on this taxonomy:
| Category | Parameter Count | Typical Use | Example Models |
|---|---|---|---|
| Tiny | < 1B | Embedded, microcontrollers, browser | Qwen2.5-0.5B, Phi-4-mini |
| Small | 1B - 3B | Mobile, IoT, on-device assistants | Gemma 3 1B, Llama 3.2 1B/3B |
| Medium | 7B - 14B | Edge servers, workstations, local APIs | Phi-4 14B, Qwen2.5-7B/14B |
| Large | 30B+ | Cloud inference, multi-GPU | GPT-4, Claude, Llama 3.1 70B |
The sweet spot for most production edge deployments in 2026 sits between 1B and 14B parameters. That is where the performance-per-watt and performance-per-dollar curves are most favorable.
The 2026 SLM Lineup: A Head-to-Head Comparison
Let us look at the models that matter right now. These are the ones we have actually deployed and benchmarked, not just read papers about.
Microsoft Phi-4
Phi-4 is Microsoft’s flagship small model family and, frankly, punches absurdly above its weight. The 14B variant regularly matches or beats models three to five times its size on reasoning tasks. Microsoft achieved this through aggressive data curation and synthetic data generation during training.
Why it stands out: Phi-4 14B scores within a few points of Llama 3.1 70B on MMLU and GSM8K while being five times smaller. The Phi-4-mini (3.8B) is a genuine workhorse for structured tasks.
Alibaba Qwen2.5 Series
The Qwen2.5 family is the most complete SLM lineup available. It spans 0.5B to 72B parameters with consistent architecture, which means your deployment pipeline works across the entire range. The instruction-tuned variants are particularly strong for multilingual applications — a critical advantage if your users are not all English speakers.
Why it stands out: Best-in-class multilingual performance at every size. The 7B variant is our go-to for edge server deployments where we need broad language coverage.
Google Gemma 3
Gemma 3 brought genuine multimodal capabilities to the small model space. The 4B variant can process both text and images, which unlocked use cases we previously needed a cloud API for — product image classification, document understanding, visual question answering, all running on a phone.
Why it stands out: Multimodal at small scale. If your use case involves images plus text, Gemma 3 is hard to beat under 10B parameters.
Meta Llama 3.2 (1B and 3B)
Meta optimized the Llama 3.2 small variants specifically for on-device deployment. They partnered with Qualcomm and MediaTek to ensure these models run efficiently on mobile chipsets with hardware acceleration. The 3B variant is genuinely capable for a model that fits in under 2 GB of RAM (quantized).
Why it stands out: Best mobile hardware integration. If you are targeting Android devices with Snapdragon chips, Llama 3.2 3B has the smoothest deployment path.
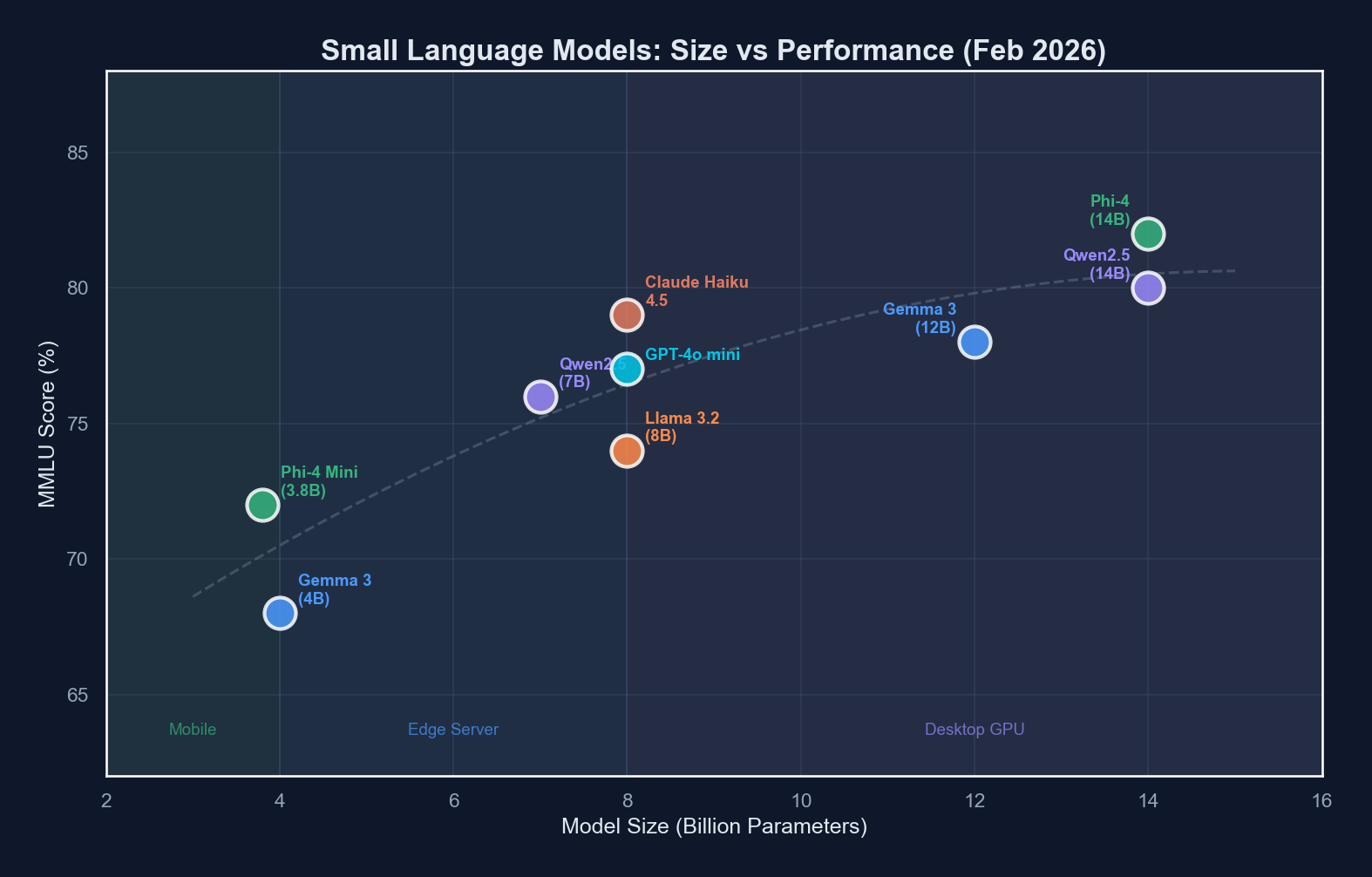 Benchmark performance scales non-linearly with parameter count — the jump from 1B to 3B is often more impactful than from 7B to 14B for common tasks.
Benchmark performance scales non-linearly with parameter count — the jump from 1B to 3B is often more impactful than from 7B to 14B for common tasks.
Benchmark Showdown: What the Numbers Actually Say
Everyone loves benchmark tables, so here they are. But a caveat first: benchmarks measure what benchmarks measure. Your actual production performance will vary based on your specific task, data distribution, and how well you fine-tune. We have found that a model scoring 5 points lower on MMLU can outperform the leader on a specific domain task after fine-tuning.
General Reasoning (MMLU / ARC-Challenge)
| Model | Params | MMLU | ARC-C | Avg Tokens/sec (A100) | Avg Tokens/sec (M4 Mac) |
|---|---|---|---|---|---|
| Phi-4 | 14B | 78.0 | 64.1 | 85 | 32 |
| Qwen2.5-14B-Instruct | 14B | 77.2 | 63.5 | 80 | 29 |
| Qwen2.5-7B-Instruct | 7B | 72.8 | 58.3 | 145 | 55 |
| Gemma 3 4B | 4B | 65.4 | 53.2 | 210 | 78 |
| Phi-4-mini | 3.8B | 68.9 | 55.7 | 220 | 80 |
| Llama 3.2 3B-Instruct | 3B | 63.2 | 51.4 | 250 | 90 |
| Qwen2.5-1.5B-Instruct | 1.5B | 56.1 | 44.8 | 380 | 140 |
| Llama 3.2 1B-Instruct | 1B | 49.3 | 39.2 | 480 | 185 |
Code Generation (HumanEval / MBPP)
| Model | Params | HumanEval | MBPP | Best For |
|---|---|---|---|---|
| Phi-4 | 14B | 72.0 | 74.5 | General coding, refactoring |
| Qwen2.5-Coder-7B | 7B | 70.1 | 72.8 | Code completion, generation |
| Phi-4-mini | 3.8B | 58.5 | 60.2 | Inline suggestions, linting |
| Llama 3.2 3B | 3B | 48.2 | 51.1 | Simple completions |
When SLMs Beat Large Models (And When They Do Not)
Here is the honest breakdown. SLMs are not universally better — they are better at specific things in specific contexts.
SLMs Win: Latency-Critical Applications
A 3B model running locally on an edge device responds in 50-100 milliseconds. A cloud API call to a large model takes 500-2000 milliseconds minimum, including network overhead. For applications like real-time autocomplete, live translation, or interactive chatbots, that difference is the entire user experience.
SLMs Win: Cost at Scale
We ran the numbers for a client processing 10 million customer support classifications per month:
| Approach | Monthly Cost | Latency (p99) | Data Privacy |
|---|---|---|---|
| GPT-4o API | $12,500 | 1,200ms | Data leaves network |
| Qwen2.5-7B on 2x L4 GPU | $1,800 | 180ms | Data stays on-premise |
| Phi-4-mini on CPU cluster | $900 | 350ms | Data stays on-premise |
| Llama 3.2 3B quantized (INT4) on CPU | $600 | 450ms | Data stays on-premise |
That is a 95% cost reduction with better latency. The trade-off is that you need to fine-tune the SLM on your specific task, which takes engineering time upfront. But once it is dialed in, the ongoing savings compound every month.
SLMs Win: Privacy and Compliance
If you operate in healthcare (HIPAA), finance (SOX), or any jurisdiction with strict data residency requirements (GDPR, India’s DPDP Act), running inference locally is not just a nice-to-have — it is a hard requirement. SLMs make local inference practical because they actually fit on the hardware you can deploy in a compliant environment.
SLMs Lose: Open-Ended Reasoning
For tasks that require broad world knowledge, multi-step logical chains, or creative writing, large models still hold a decisive advantage. A 3B model will not write a nuanced legal brief or debug a complex distributed systems issue as well as GPT-4 or Claude. Know your task complexity.
SLMs Lose: Zero-Shot Generalization
Large models handle novel task formats with minimal prompting. SLMs typically need fine-tuning or at least carefully crafted few-shot prompts to match. If your use case changes frequently and unpredictably, the engineering overhead of constantly re-tuning an SLM may outweigh the cost savings.
Deployment Patterns: Where SLMs Actually Run
Pattern 1: Mobile (iOS / Android)
Running a model directly on a user’s phone eliminates server costs entirely for inference and provides offline capability.
Best models: Llama 3.2 1B/3B, Gemma 3 1B, Qwen2.5-1.5B
Typical stack:
# Convert model to mobile-optimized format
# Using llama.cpp for cross-platform mobile deployment
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp && make
# Quantize to 4-bit for mobile
python3 convert_hf_to_gguf.py \
--model meta-llama/Llama-3.2-3B-Instruct \
--outfile llama-3.2-3b-instruct.gguf
./llama-quantize \
llama-3.2-3b-instruct.gguf \
llama-3.2-3b-instruct-q4_k_m.gguf Q4_K_MThe Q4_K_M quantized Llama 3.2 3B model comes in at roughly 1.8 GB — small enough for most modern phones with 6+ GB of RAM. On a Snapdragon 8 Gen 3, it generates around 15-20 tokens per second, which is fast enough for real-time conversational use.
# Python example: local inference with llama-cpp-python
from llama_cpp import Llama
llm = Llama(
model_path="./llama-3.2-3b-instruct-q4_k_m.gguf",
n_ctx=2048,
n_threads=4, # Match device CPU cores
n_gpu_layers=0, # CPU-only for broad compatibility
)
response = llm.create_chat_completion(
messages=[
{"role": "system", "content": "Classify the support ticket intent."},
{"role": "user", "content": "My order hasn't arrived and it's been 10 days."},
],
max_tokens=50,
temperature=0.1,
)
print(response["choices"][0]["message"]["content"])
# Output: "shipping_delay"Pattern 2: IoT and Edge Gateways
For industrial IoT, retail edge, or smart building applications, SLMs run on compact edge hardware like NVIDIA Jetson, Intel NUC, or even Raspberry Pi 5.
Best models: Qwen2.5-0.5B, Llama 3.2 1B, Phi-4-mini (if GPU available)
# Docker Compose for edge deployment with Ollama
version: "3.8"
services:
ollama:
image: ollama/ollama:latest
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
deploy:
resources:
limits:
memory: 4G
environment:
- OLLAMA_NUM_PARALLEL=2
inference-api:
build: ./inference-service
ports:
- "8080:8080"
environment:
- OLLAMA_HOST=http://ollama:11434
- MODEL_NAME=qwen2.5:1.5b
- MAX_TOKENS=256
depends_on:
- ollama
volumes:
ollama_data:Pattern 3: In-Browser (WebGPU / WebAssembly)
This is the deployment pattern that surprises people the most. You can run a 1B parameter model directly in the user’s browser with no server at all. Zero infrastructure cost. Zero data transmission.
Best models: Qwen2.5-0.5B, Llama 3.2 1B (quantized to INT4)
# Server-side: prepare the model for web deployment
# Using MLC LLM to compile for WebGPU
pip install mlc-llm
mlc_llm convert_weight \
--model Qwen/Qwen2.5-0.5B-Instruct \
--quantization q4f16_1 \
--output dist/qwen2.5-0.5b-q4f16
mlc_llm gen_config \
--model Qwen/Qwen2.5-0.5B-Instruct \
--quantization q4f16_1 \
--output dist/qwen2.5-0.5b-q4f16The compiled Qwen2.5-0.5B model weighs about 350 MB in INT4 quantization. On a laptop with a decent GPU (RTX 3060 or Apple M-series), it runs at 30+ tokens per second in Chrome via WebGPU. On older hardware without WebGPU support, WASM fallback still manages 5-10 tokens per second.
 A typical edge deployment architecture: models are quantized once, then distributed to heterogeneous devices from phones to edge servers.
A typical edge deployment architecture: models are quantized once, then distributed to heterogeneous devices from phones to edge servers.
Quantization: Making Models Fit Where They Need to Go
Quantization is the single most impactful technique for edge deployment. It reduces model size and increases inference speed by representing weights with fewer bits, at a small cost to accuracy.
Quantization Methods Compared
| Method | Bits | Size Reduction | Speed Gain | Quality Loss | Best For |
|---|---|---|---|---|---|
| FP16 (baseline) | 16 | 1x | 1x | None | GPU servers |
| INT8 (absmax) | 8 | 2x | 1.5-2x | Minimal | Edge servers with GPU |
| INT4 (GPTQ) | 4 | 4x | 2-3x | Small | Mobile, edge CPU |
| INT4 (AWQ) | 4 | 4x | 2-3x | Very small | Mobile, edge CPU |
| Q4_K_M (GGUF) | 4 mixed | 4x | 2-3x | Very small | CPU inference (llama.cpp) |
| INT3 / INT2 | 2-3 | 5-8x | 3-4x | Noticeable | Extreme edge, IoT |
For most production deployments, Q4_K_M (4-bit with importance-based mixed precision) hits the optimal trade-off. Here is what that looks like in practice:
# Quantize a Hugging Face model with AutoGPTQ
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
model_id = "microsoft/phi-4"
quantize_config = BaseQuantizeConfig(
bits=4,
group_size=128,
damp_percent=0.01,
desc_act=True,
sym=False,
)
model = AutoGPTQForCausalLM.from_pretrained(
model_id,
quantize_config=quantize_config,
torch_dtype="auto",
)
# Calibration dataset - use representative samples from YOUR domain
model.quantize(calibration_dataset)
# Save quantized model
model.save_quantized("./phi-4-gptq-int4")Real-World Size and Performance After Quantization
| Model | Original (FP16) | Q4_K_M | RAM Required | Tokens/sec (M4 Mac) |
|---|---|---|---|---|
| Phi-4 14B | 28 GB | 8.1 GB | ~10 GB | 32 |
| Qwen2.5-7B | 14 GB | 4.2 GB | ~6 GB | 55 |
| Phi-4-mini 3.8B | 7.6 GB | 2.3 GB | ~4 GB | 80 |
| Llama 3.2 3B | 6 GB | 1.8 GB | ~3 GB | 90 |
| Qwen2.5-1.5B | 3 GB | 1.0 GB | ~2 GB | 140 |
| Llama 3.2 1B | 2 GB | 0.7 GB | ~1.5 GB | 185 |
Practical Use Cases We Have Actually Shipped
Let me share five real deployments where SLMs outperformed cloud LLM APIs for our clients.
1. Customer Support Intent Classification
Model: Qwen2.5-1.5B fine-tuned on 50K labeled tickets Deployment: Kubernetes pods with CPU-only inference Result: 94.2% accuracy (vs. 96.1% for GPT-4o), 40ms p99 latency (vs. 1,100ms), $600/mo (vs. $14,000/mo)
The 2% accuracy gap was irrelevant because misclassified tickets were caught by a human review step anyway. The latency improvement transformed the user experience.
2. On-Device Receipt Scanner
Model: Gemma 3 1B with vision, quantized INT4 Deployment: Android app (Samsung Galaxy S24, Pixel 9) Result: Extracts merchant, amount, date, and line items from receipt photos in 800ms on-device. Works fully offline. No data ever leaves the phone.
3. Real-Time Manufacturing Anomaly Detection
Model: Phi-4-mini fine-tuned on sensor log descriptions Deployment: NVIDIA Jetson Orin at factory edge Result: Classifies sensor anomaly descriptions and generates human-readable alerts in under 200ms. Previously required a round-trip to a cloud API (1.5 second latency was causing missed real-time alerts).
4. Browser-Based Writing Assistant
Model: Qwen2.5-0.5B compiled for WebGPU Deployment: Chrome extension, zero server infrastructure Result: Grammar correction and sentence rephrasing running entirely in the browser. Serves 50,000+ daily active users with $0 in inference costs. The entire infrastructure is a static file CDN serving the model weights.
5. Multilingual Chatbot for Retail Kiosks
Model: Qwen2.5-7B-Instruct on Intel NUC with Arc GPU Deployment: In-store kiosks across 200 locations Result: Handles customer queries in 12 languages without an internet connection. Crucial for locations with unreliable connectivity. The NUC hardware costs $800 per unit — paid for itself in two months of saved API costs.
Getting Started: A Decision Framework
If you are considering SLMs for your next project, here is how we think about model selection:
Step 1: Define your latency budget. Under 100ms? You need on-device or edge. Under 500ms? Edge server works. Over 500ms? Cloud API is fine, and you probably do not need an SLM.
Step 2: Define your hardware constraints. Phone (1-3B, quantized). Edge server with GPU (7-14B). Edge server CPU-only (1-7B, quantized). Browser (0.5-1B, quantized).
Step 3: Define your task complexity. Single-task classification or extraction? 1-3B is plenty. Multi-step reasoning or code generation? 7-14B. Open-ended conversation with world knowledge? Consider a cloud API or 14B+ model.
Step 4: Fine-tune, do not prompt-engineer. With large models you can get away with clever prompting. SLMs need fine-tuning to hit production quality. Budget 1-2 weeks for data preparation and training. Use LoRA — it works remarkably well and keeps training costs under $50 for most models on a single GPU.
# Quick LoRA fine-tuning with Unsloth (2x faster than standard PEFT)
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="microsoft/phi-4-mini",
max_seq_length=2048,
load_in_4bit=True,
)
model = FastLanguageModel.get_peft_model(
model,
r=16,
lora_alpha=32,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
lora_dropout=0.05,
)
# Train with your domain-specific dataset
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
train_dataset=your_dataset,
dataset_text_field="text",
max_seq_length=2048,
args=TrainingArguments(
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
warmup_steps=50,
num_train_epochs=3,
learning_rate=2e-4,
output_dir="./phi4-mini-finetuned",
),
)
trainer.train()
# Export to GGUF for edge deployment
model.save_pretrained_gguf(
"phi4-mini-finetuned-gguf",
tokenizer,
quantization_method="q4_k_m",
)The Bottom Line
The SLM landscape in 2026 has matured to the point where reaching for a cloud API should be a deliberate choice, not a default. For the majority of production NLP tasks — classification, extraction, summarization, translation, simple Q&A — a fine-tuned model between 1B and 7B parameters running on modest hardware will deliver better latency, dramatically lower costs, and complete data privacy.
The large models are not going anywhere, and they are still the right choice for complex reasoning, creative tasks, and rapid prototyping. But for the bread-and-butter inference workloads that make up 80% of production deployments, small models are not a compromise. They are the better engineering decision.
Start small. Literally. Pick your most straightforward classification task, fine-tune a Qwen2.5-1.5B or Phi-4-mini on it, deploy it on whatever hardware you have, and measure the results. I think you will be surprised how rarely you reach for GPT-4 after that.
Sponsored
More from this category
More from AI Integration
 R.01
R.01 Document AI for Agencies: Extracting Structure from PDFs, Forms, and Contracts
 R.02
R.02 AI Video Generation in 2026: What Agencies Need to Know Before Pitching It to Clients
 R.03
R.03 Browser-Use Agents: Automating the Web When APIs Don't Exist
Sponsored
Discussion
Join the conversation.
Comments are powered by GitHub Discussions. Sign in with your GitHub account to leave a comment.
Sponsored