AI Integration · Developer Tools
GPT-5.3 Codex vs Claude Opus 4.6: The AI Coding War of 2026, Compared
OpenAI and Anthropic released their flagship coding models on the same day. We compare GPT-5.3 Codex and Claude Opus 4.6 across benchmarks, pricing, developer experience, and real-world coding tasks.

Anurag Verma
9 min read

Sponsored
February 5, 2026 will go down as one of the most consequential days in the history of AI-assisted development. On the exact same day, OpenAI released GPT-5.3 Codex and Anthropic shipped Claude Opus 4.6: two models that represent the absolute frontier of AI coding capability. The timing was no coincidence, and the resulting head-to-head comparison has consumed the developer community ever since.
We have spent the past several days testing both models extensively across real-world coding tasks, studying the benchmark data, and comparing developer experience. Here is our comprehensive, honest breakdown of how these two titans stack up.
The Release Context
Both companies clearly viewed this as a defining moment. OpenAI positioned GPT-5.3 Codex as the evolution from code assistant to autonomous software engineer: a model that can plan, execute, debug, and ship entire features with minimal supervision. Anthropic positioned Opus 4.6 as the thinking developer’s model, emphasizing deep reasoning, massive context windows, and collaborative multi-agent workflows.
These are not just incremental upgrades. Both represent fundamental shifts in what AI coding assistants can do.
Benchmark Comparison
Let us start with the numbers. Here is how the models compare on the major coding and reasoning benchmarks:
| Benchmark | GPT-5.3 Codex | Claude Opus 4.6 | Notes |
|---|---|---|---|
| SWE-Bench Pro | 56.8% | 54.2% | Real-world GitHub issue resolution |
| SWE-Bench Verified | 76.1% | 79.4% | Curated subset with verified solutions |
| Terminal-Bench 2.0 | 77.3% | 71.8% | Autonomous terminal operations |
| GPQA Diamond | 72.1% | 77.3% | Graduate-level reasoning |
| MMLU Pro | 82.4% | 85.1% | Professional knowledge tasks |
| HumanEval+ | 94.2% | 93.8% | Code generation accuracy |
| OSWorld | 62.4% | 58.1% | Operating system interaction |
The picture that emerges is nuanced. GPT-5.3 Codex leads on execution-oriented benchmarks — tasks that require autonomous action, terminal operations, and rapid code generation. Opus 4.6 leads on reasoning-heavy benchmarks — tasks that require deep thinking, complex analysis, and academic-level problem solving.
Neither model dominates across the board. Your choice should depend on your primary use case.
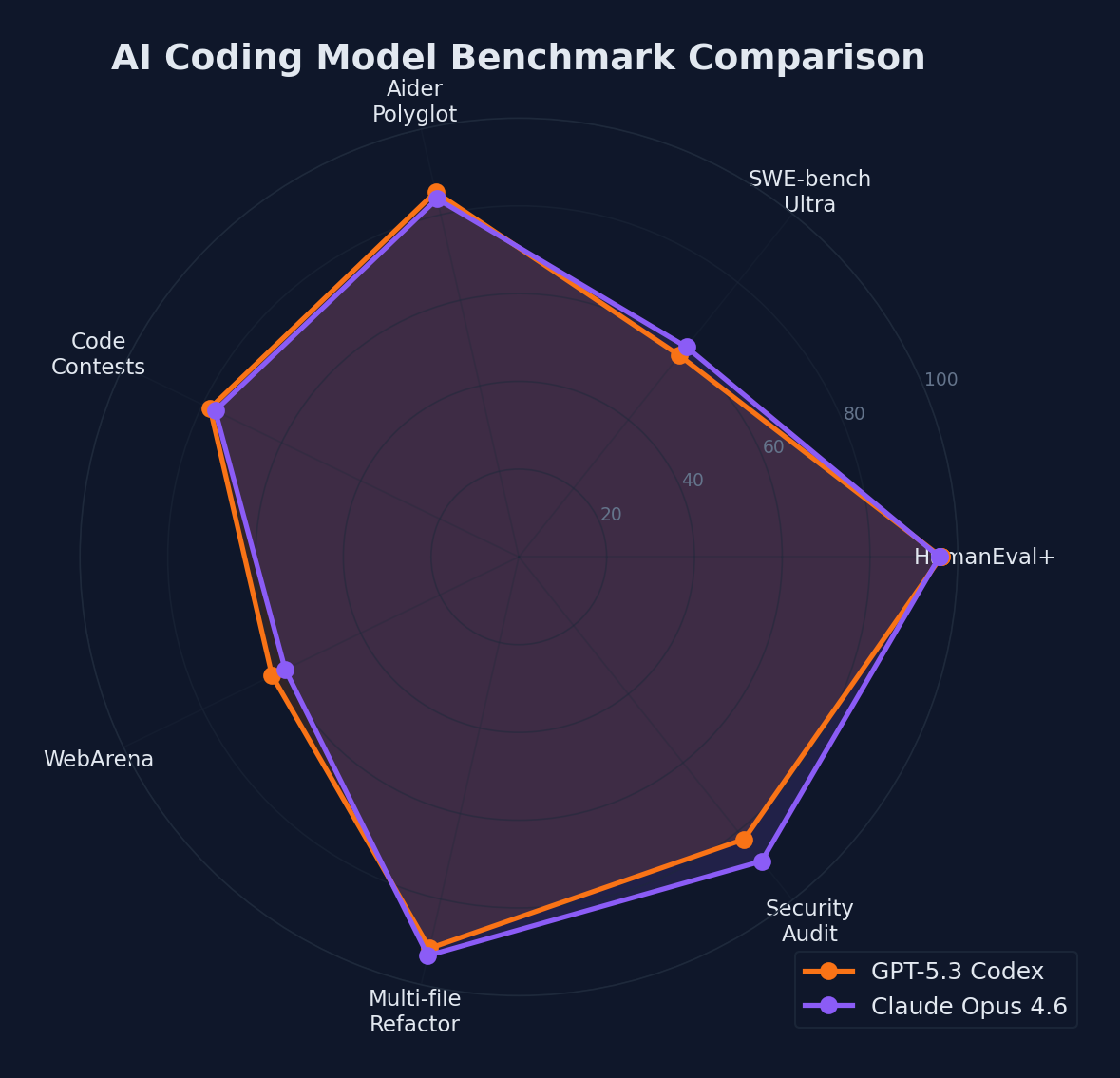 Benchmark comparison across seven key coding evaluation metrics
Benchmark comparison across seven key coding evaluation metrics
Architecture and Design Philosophy
GPT-5.3 Codex: The Autonomous Executor
OpenAI’s design philosophy with Codex is clear: build a model that can do the work with minimal human intervention. Key architectural decisions include:
- Agentic execution loop: Codex is built from the ground up for autonomous multi-step task completion. It can plan a task, execute code, observe results, debug failures, and iterate, all without human input.
- Interactive steering: A new feature allows developers to watch Codex work in real-time and intervene (asking questions, suggesting different approaches, or redirecting) without losing context.
- Token efficiency: OpenAI claims Codex accomplishes equivalent tasks with less than half the tokens of its predecessor, translating to significant cost savings.
- 25% faster inference: Per-token generation speed has improved by 25% over GPT-5.2 Codex.
Claude Opus 4.6: The Reasoning Collaborator
Anthropic’s approach prioritizes depth over speed:
- 1M token context window: For the first time on an Opus-class model, supporting analysis of entire codebases in a single context.
- Agent Teams: A research preview feature where multiple Claude agents work simultaneously on different aspects of a project (one on the frontend, one on the API, one on database migrations) coordinating autonomously.
- 128K token output: Opus 4.6 can generate up to 128,000 tokens in a single response, enabling generation of entire features or modules in one pass.
- Context compaction: Automatic summarization of older context when conversations approach limits, enabling longer sustained work sessions.
Pricing Comparison
Pricing is a crucial factor for teams evaluating these models:
| GPT-5.3 Codex | Claude Opus 4.6 | |
|---|---|---|
| Input (per 1M tokens) | TBD (API not yet public) | $5.00 |
| Output (per 1M tokens) | TBD (API not yet public) | $25.00 |
| Premium input (>200K context) | N/A | $10.00 |
| Premium output (>200K context) | N/A | $37.50 |
| Consumer access | ChatGPT Plus/Pro subscription | Claude Pro subscription |
| API availability | Coming soon | Available now |
A significant note: at the time of writing, GPT-5.3 Codex is only available through ChatGPT subscriptions. API access has been announced but not yet launched. Opus 4.6, by contrast, is available immediately via the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Azure Foundry. For teams building production tooling, this availability gap matters.
Real-World Coding: Head-to-Head Tests
Benchmarks tell part of the story. Here is what we observed in real-world usage:
Test 1: Refactoring a Legacy Express.js API to Fastify
We gave both models a 2,000-line Express.js API and asked them to refactor it to Fastify while maintaining all existing tests.
GPT-5.3 Codex completed the task in approximately 4 minutes, working autonomously through the codebase file by file. It made several smart decisions: converting middleware patterns correctly, updating route handlers, and adjusting error handling. However, it missed a subtle difference in how Fastify handles request validation schemas versus Express middleware, causing 3 test failures that required manual intervention.
Claude Opus 4.6 took approximately 7 minutes but produced a more thorough refactoring. It identified the validation schema difference upfront and addressed it proactively. It also generated detailed comments explaining each architectural decision. All tests passed on the first run.
Verdict: Codex is faster. Opus is more thorough. For a senior developer who can quickly spot and fix the validation issue, Codex’s speed advantage wins. For a team that needs a correct-on-first-pass result, Opus is the safer choice.
Test 2: Debugging a Race Condition in a Go Microservice
We presented both models with a Go microservice exhibiting an intermittent race condition under load.
GPT-5.3 Codex identified the race condition within 2 minutes by analyzing the goroutine lifecycle and channel usage. It proposed a fix using sync.Mutex that was correct but not optimal.
// Codex's fix - correct but uses coarse-grained locking
var mu sync.Mutex
func (s *Service) ProcessOrder(ctx context.Context, order *Order) error {
mu.Lock()
defer mu.Unlock()
// ... processing logic
}Claude Opus 4.6 took 4 minutes but identified not only the primary race condition but also a secondary data race in the logging middleware that had not been reported. Its fix used sync.RWMutex with fine-grained locking:
// Opus 4.6's fix - fine-grained locking with read/write separation
type Service struct {
mu sync.RWMutex
ordersMu sync.Mutex
// ...
}
func (s *Service) ProcessOrder(ctx context.Context, order *Order) error {
s.ordersMu.Lock()
defer s.ordersMu.Unlock()
// ... write path with order-specific lock
}
func (s *Service) GetOrderStatus(ctx context.Context, id string) (*Status, error) {
s.mu.RLock()
defer s.mu.RUnlock()
// ... read path with shared lock
}Verdict: Opus 4.6 wins clearly here. The ability to identify multiple related issues and produce a more architecturally sound fix is exactly what you want when debugging concurrency problems.
Test 3: Full-Stack Feature Implementation
We asked both models to implement a complete user notification preferences feature: database migration, API endpoints, React UI with real-time updates via WebSockets.
GPT-5.3 Codex excelled here. Its autonomous execution loop meant it could scaffold the database migration, create the API routes, build the React components, and wire up the WebSocket connection in a single flow. It even ran the migration and tests autonomously.
Claude Opus 4.6 with Agent Teams was impressive in a different way, splitting the work across frontend, backend, and database agents. However, the Agent Teams feature is still in research preview, and we observed occasional coordination hiccups between agents.
Verdict: Codex wins for autonomous feature implementation today. Agent Teams has enormous potential but needs more maturity.
Developer Experience
GPT-5.3 Codex
- Strengths: Real-time interactive steering is genuinely useful. The ability to watch the model work and course-correct without losing context feels like pair programming with a very fast junior developer.
- Weaknesses: The ChatGPT-only access limitation is frustrating for teams that need API integration. The model can be overconfident, sometimes plowing ahead with an incorrect approach rather than pausing to ask for clarification.
Claude Opus 4.6
- Strengths: The 1M context window is a game-changer for large codebases. The model excels at understanding existing code before making changes. Claude Code integration with Agent Teams, while still in preview, hints at the future of multi-agent development.
- Weaknesses: Slower than Codex for straightforward tasks. The premium pricing for >200K token contexts adds up quickly when analyzing large projects.
Which Should You Choose?
Here is our honest recommendation based on extensive testing:
Choose GPT-5.3 Codex if you:
- Prioritize speed and autonomous execution
- Work primarily on feature implementation and scaffolding
- Want interactive, real-time collaboration with the AI
- Are comfortable reviewing and correcting AI output
- Primarily use ChatGPT as your interface
Choose Claude Opus 4.6 if you:
- Work with large, complex codebases that benefit from the 1M context window
- Prioritize correctness over speed
- Need deep reasoning for debugging, security analysis, or architecture review
- Want API access for building custom tooling today
- Are interested in multi-agent workflows (Agent Teams)
For many teams, the answer is both. These models have complementary strengths. Use Codex for rapid feature development and Opus for code review, debugging, and security analysis. The $20-30/month subscription cost for both is trivial compared to developer productivity gains.
The Convergence Ahead
What is most striking about this comparison is not the differences. It is the convergence. Both models are moving toward the same destination: fully autonomous software engineering agents that can handle entire development workflows end-to-end. They are just approaching it from different angles.
OpenAI is building from execution toward reasoning. Anthropic is building from reasoning toward execution. By the end of 2026, the gap between them will likely narrow further. The real winners are developers, who now have two extraordinary tools competing for their attention, and that competition is driving innovation at a pace that would have seemed impossible just a year ago.
Sponsored
More from this category
More from AI Integration
 R.01
R.01 Document AI for Agencies: Extracting Structure from PDFs, Forms, and Contracts
 R.02
R.02 AI Video Generation in 2026: What Agencies Need to Know Before Pitching It to Clients
 R.03
R.03 Browser-Use Agents: Automating the Web When APIs Don't Exist
Sponsored
Discussion
Join the conversation.
Comments are powered by GitHub Discussions. Sign in with your GitHub account to leave a comment.
Sponsored