AI Integration · Security
Claude Opus 4.6 Found 500+ Zero-Day Vulnerabilities: How AI Is Revolutionizing Security Research
Anthropic's Claude Opus 4.6 discovered over 500 previously unknown high-severity vulnerabilities in open-source software. Here's what this means for cybersecurity, developers, and the future of AI-powered security research.

Anurag Verma
7 min read

Sponsored
On February 5, 2026, Anthropic released Claude Opus 4.6 — and with it, a revelation that sent shockwaves through the cybersecurity industry. During internal testing, the model discovered over 500 previously unknown zero-day vulnerabilities in some of the most battle-tested open-source codebases on the planet. These were not theoretical weaknesses. Every single finding was validated by either a member of Anthropic’s Frontier Red Team or an independent security researcher.
This is a watershed moment. For decades, vulnerability research has been the domain of highly skilled human specialists armed with fuzzers, debuggers, and deep institutional knowledge. Now, an AI model — given nothing more than standard tools and no specialized instructions — has matched or exceeded the output of entire security teams. Let us break down what happened, how it works, and what it means for everyone building software today.
What Anthropic’s Frontier Red Team Actually Did
Anthropic’s Frontier Red Team placed Claude Opus 4.6 inside a sandboxed virtual machine with access to:
- Python runtime
- Standard vulnerability analysis tools (debuggers, fuzzers)
- The latest versions of popular open-source projects
Critically, the model received no specific instructions on how to find vulnerabilities. No specialized prompts, no curated datasets of known vulnerability patterns, no hand-holding. The team simply pointed Opus 4.6 at well-known codebases and let it work.
The result: over 500 high-severity, previously unknown zero-day vulnerabilities — discovered using nothing but the model’s “out-of-the-box” capabilities.
Notable Vulnerabilities Discovered
Among the specific findings that Anthropic has disclosed publicly:
GhostScript (PDF/PostScript Processing)
Opus 4.6 identified a vulnerability in GhostScript — a widely deployed utility for processing PDF and PostScript files — that could crash systems processing maliciously crafted documents. Given that GhostScript is embedded in countless server-side document processing pipelines, the blast radius of this bug was significant.
OpenSC (Smart Card Processing)
Buffer overflow vulnerabilities were discovered in OpenSC, the open-source smart card tools and middleware package. Smart cards are used in everything from corporate authentication to government ID systems, making this finding particularly sensitive.
CGIF (GIF Processing Library)
Perhaps the most technically impressive discovery was a buffer overflow in CGIF, a library for creating GIF images. Anthropic noted that “this vulnerability is particularly interesting because triggering it requires a conceptual understanding of the LZW algorithm and how it relates to the GIF file format.” In other words, the model did not just pattern-match against known bug types — it reasoned about algorithmic behavior to identify a novel attack vector.
How Opus 4.6 Finds Vulnerabilities
What makes Opus 4.6’s approach remarkable is that it mirrors the methodology of expert human security researchers rather than brute-force automated tools:
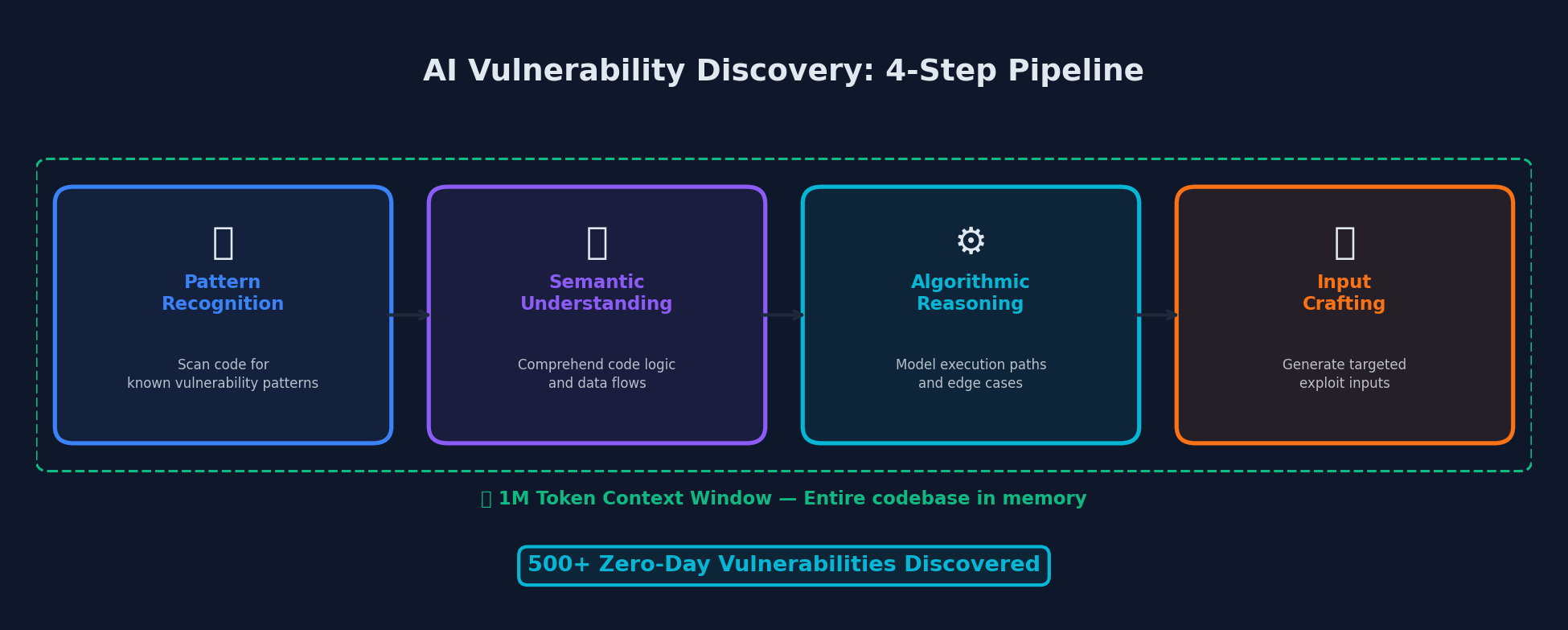 Claude Opus 4.6’s four-step vulnerability discovery pipeline, powered by a 1M token context window
Claude Opus 4.6’s four-step vulnerability discovery pipeline, powered by a 1M token context window
-
Pattern Recognition from Past Fixes: The model examines historical patches and commit logs, identifying patterns where similar bugs were fixed — then looks for analogous issues that were missed.
-
Semantic Code Understanding: Rather than relying purely on static analysis rules, Opus 4.6 reads and reasons about code with genuine comprehension of the underlying logic, data flows, and trust boundaries.
-
Algorithmic Reasoning: As demonstrated by the CGIF finding, the model can reason about complex algorithms (like LZW compression) and understand how specific inputs could trigger unexpected behavior.
-
Input Crafting: Once a potential vulnerability is identified, Opus 4.6 can generate proof-of-concept inputs that trigger the flaw, providing concrete validation.
This represents a fundamentally different approach from traditional automated vulnerability discovery tools like fuzzers. Fuzzers have had decades of CPU time thrown at these same codebases — yet Opus 4.6 found bugs they missed, because many of these vulnerabilities require conceptual understanding that random input generation cannot replicate.
The 1M Context Window Advantage
One often-overlooked factor in these security results is Opus 4.6’s new 1-million-token context window. For the first time, an Opus-class model can hold entire codebases in context simultaneously. On the 8-needle 1M variant of MRCR v2 — a needle-in-a-haystack benchmark — Opus 4.6 scores 76%, compared to just 18.5% for Sonnet 4.5.
For security research, this is transformative. Many real-world vulnerabilities span multiple files, involving complex interactions between components that are difficult to track when limited to small context windows. With 1M tokens, Opus 4.6 can analyze cross-module data flows, understand how trust boundaries are (or are not) maintained across function boundaries, and trace user input from entry point to dangerous sink across an entire project.
Anthropic’s New Cybersecurity Safeguards
Anthropic acknowledges the dual-use nature of these capabilities head-on. The same model that helps defenders find and fix vulnerabilities could, in the wrong hands, help attackers discover and exploit them before patches are available.
To address this, Anthropic has developed six new cybersecurity-specific probes that operate at inference time:
- These probes measure model activations during response generation
- They allow Anthropic to detect specific forms of cybersecurity misuse at scale
- The probes enable real-time monitoring of Claude’s internal activity as it generates responses
- Traffic identified as potentially malicious can be blocked automatically
Anthropic has also expanded its enforcement capabilities, including the ability to flag and block traffic patterns consistent with offensive exploitation rather than defensive research.
The company acknowledges this will create friction for legitimate security researchers and has committed to working with the security research community to find the right balance.
What This Means for Developers
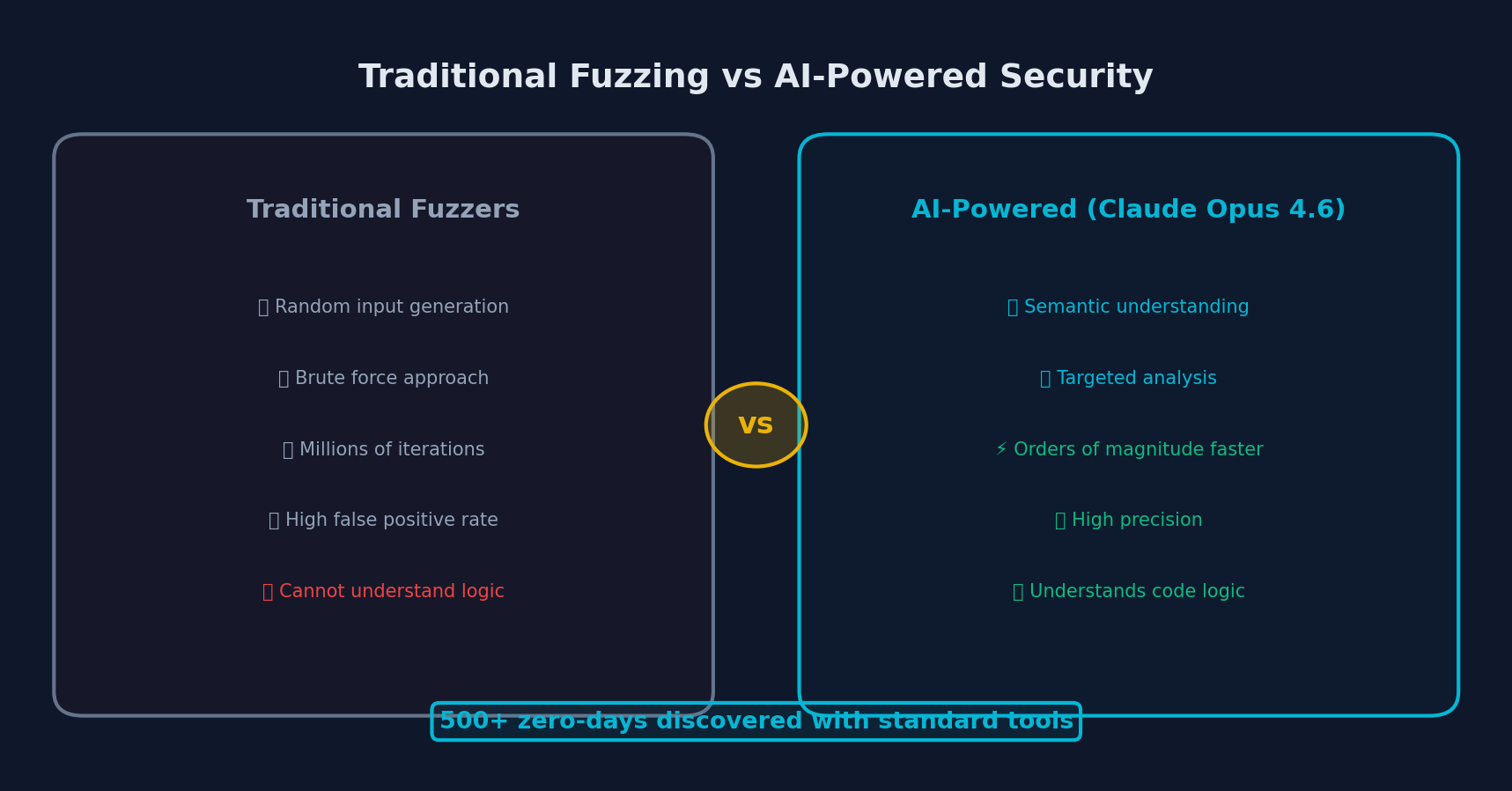 How AI-powered vulnerability discovery compares to traditional fuzzing approaches
How AI-powered vulnerability discovery compares to traditional fuzzing approaches
Integrate AI-Powered Security Scanning Into Your CI/CD
The era of relying solely on traditional SAST/DAST tools is ending. Consider integrating AI-powered code review into your development pipeline:
# Example: GitHub Actions workflow with AI security review
name: AI Security Review
on:
pull_request:
branches: [main]
jobs:
security-review:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Run AI Security Analysis
uses: anthropic/claude-security-action@v2
with:
api-key: ${{ secrets.ANTHROPIC_API_KEY }}
model: claude-opus-4-6
scan-type: differential
severity-threshold: mediumPrioritize Dependency Updates
Many of the 500+ vulnerabilities were in widely-used libraries. Ensure your dependency management is robust:
# Audit your Node.js dependencies
npm audit --audit-level=high
# Check for known vulnerabilities in Python packages
pip-audit --strict
# Use Anthropic's published CVE feed for the latest findings
curl -s https://red.anthropic.com/api/v1/cves/latest | jq '.vulnerabilities[]'Rethink Your Threat Model
If an AI can find 500+ zero-days in well-audited codebases, your code — which has received far less scrutiny — almost certainly contains similar issues. This is not a reason to panic, but it is a reason to:
- Increase fuzzing budgets for critical code paths
- Adopt memory-safe languages (Rust, Go) for new security-critical components
- Implement defense-in-depth assuming that vulnerabilities exist in every layer
- Enable sandboxing for code that processes untrusted input (containers, seccomp, pledge/unveil)
The Bigger Picture: AI as a Force Multiplier for Security
The security industry has long faced a severe talent shortage. There are not enough skilled vulnerability researchers to audit even a fraction of the open-source code that modern software depends on. AI models like Opus 4.6 do not replace human researchers — but they dramatically amplify their effectiveness.
Consider the economics: a human security researcher might audit one complex codebase per quarter. Opus 4.6 can analyze hundreds of projects in the time it takes to run the analysis. When the human researcher then reviews and validates the AI’s findings, the combination is orders of magnitude more productive than either working alone.
This is the model that will likely define the next era of cybersecurity: AI as a tireless, capable first-pass auditor, with human experts providing judgment, context, and strategic direction.
Looking Ahead
Anthropic has indicated that vulnerability disclosure for the 500+ findings is being handled through responsible disclosure processes with affected maintainers. Many patches are already in progress.
For the cybersecurity industry, February 2026 will be remembered as the month when AI-powered vulnerability research went from experimental curiosity to production reality. The implications are profound — for defenders who now have a powerful new tool, and for the entire software ecosystem that must reckon with the fact that the bar for finding vulnerabilities just dropped dramatically.
The question is no longer whether AI will transform security research. The question is whether defenders will adopt these tools fast enough to stay ahead of attackers who are doing the same.
Sponsored
More from this category
More from AI Integration
 R.01
R.01 Document AI for Agencies: Extracting Structure from PDFs, Forms, and Contracts
 R.02
R.02 AI Video Generation in 2026: What Agencies Need to Know Before Pitching It to Clients
 R.03
R.03 Browser-Use Agents: Automating the Web When APIs Don't Exist
Sponsored
Discussion
Join the conversation.
Comments are powered by GitHub Discussions. Sign in with your GitHub account to leave a comment.
Sponsored