AI Integration · Industry News
Claude Opus 4.6 Is Here — Agent Teams, 1 Million Token Context, and a Direct Challenge to OpenAI
Anthropic just dropped Claude Opus 4.6 with game-changing features: agent teams that work in parallel, a 1 million token context window, and benchmarks that put OpenAI on notice. Here's everything you need to know.

Anurag Verma
15 min read
Sponsored
Anthropic dropped Claude Opus 4.6 yesterday, and the AI world is still processing what just happened. Within 20 minutes of the announcement, OpenAI rushed out GPT-5.3 Codex in what can only be described as a panic response. That timing tells you everything you need to know about how significant this release is.
But beyond the industry drama, Opus 4.6 introduces features that fundamentally change how developers can work with AI. Agent teams, a 1 million token context window, adaptive thinking controls, and Microsoft Office integrations are not incremental improvements. They represent a shift in what is possible.
Let me break down everything you need to know.
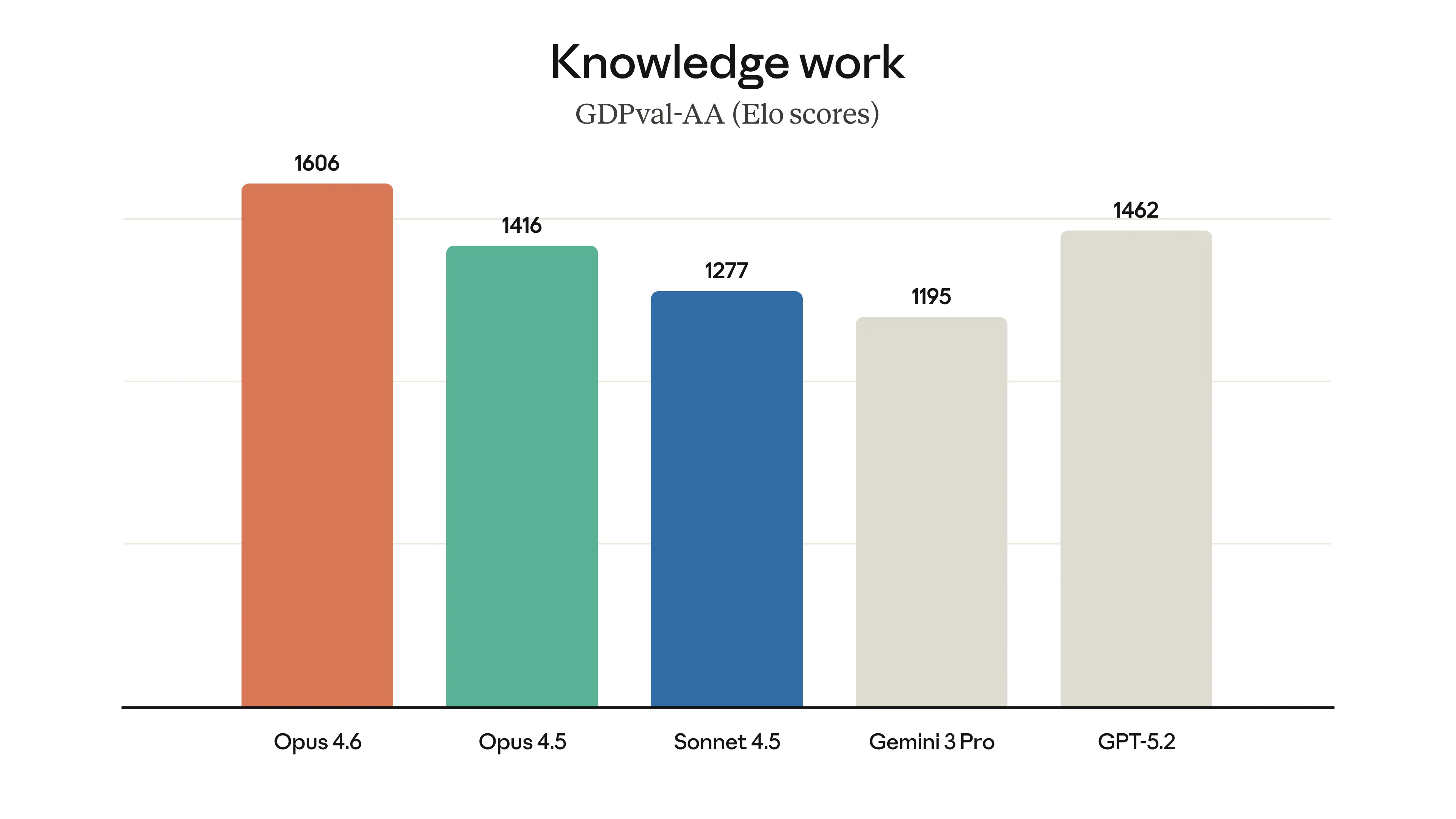
Opus 4.6 leads all competitors on knowledge work tasks with an Elo score of 1606
Quick Overview: What’s New in Opus 4.6
Before we dive deep, here’s a snapshot of the key changes:
| Feature | Opus 4.5 | Opus 4.6 | Improvement |
|---|---|---|---|
| Context Window | 200K tokens | 1M tokens | 5x increase |
| Max Output | 32K tokens | 128K tokens | 4x increase |
| GPQA Diamond | 87.0% | 91.3% | +4.3 points |
| Terminal-Bench 2.0 | 59.8% | 65.4% | +5.6 points |
| BrowseComp | 67.8% | 84.0% | +16.2 points |
| ARC AGI 2 | 37.6% | 68.8% | +31.2 points |
| Humanity’s Last Exam | 30.8% | 40.0% | +9.2 points |
| MRCR v2 (1M) | N/A | 76.0% | New capability |
| Agent Teams | No | Yes | New feature |
| Adaptive Thinking | No | Yes | New feature |
| Office Integration | Excel only | Excel + PowerPoint | Expanded |
The pricing remains unchanged at $5/$25 per million tokens (input/output), making this a pure capability upgrade.
Agent Teams: The Headline Feature
This is the feature that has developers most excited. Instead of one AI agent working through tasks sequentially, you can now spin up multiple Claude instances that coordinate autonomously.
How Agent Teams Work
Agent Teams Architecture
┌─────────────────────────────────────────────────────────────┐
│ TEAM LEAD │
│ (Main Claude Code Session) │
│ • Creates team and assigns objectives │
│ • Spawns teammates │
│ • Synthesizes final results │
└─────────────────────┬───────────────────────────────────────┘
│
┌─────────────┼─────────────┐
│ │ │
▼ ▼ ▼
┌───────────┐ ┌───────────┐ ┌───────────┐
│ TEAMMATE │ │ TEAMMATE │ │ TEAMMATE │
│ A │ │ B │ │ C │
│ │ │ │ │ │
│ Own │ │ Own │ │ Own │
│ context │ │ context │ │ context │
│ window │ │ window │ │ window │
└─────┬─────┘ └─────┬─────┘ └─────┬─────┘
│ │ │
└──────────────┼──────────────┘
│
┌──────▼──────┐
│ SHARED │
│ TASK LIST │
│ │
│ • Claim │
│ • Update │
│ • Complete │
└─────────────┘Key characteristics:
- Team Lead: Your main Claude Code session that creates the team, spawns teammates, assigns tasks, and synthesizes results
- Teammates: Independent sessions with their own context windows
- Direct Communication: Team members can message each other directly
- Shared Task List: Agents claim tasks, update progress, and report completion
- Parallel Execution: Everything happens simultaneously without constant human intervention
Real-World Demonstration
Anthropic demonstrated agent teams by having them build a 100,000-line C compiler from scratch, one that can compile Linux 6.9 for x86, ARM, and RISC-V architectures. This is not a toy demo. This is production-grade code generated through AI coordination.
Best Use Cases for Agent Teams
| Use Case | How It Works | Benefit |
|---|---|---|
| Code Review | Multiple agents examine code from different angles | Catches issues a single agent misses |
| Multi-Module Development | Different agents build different modules in parallel | Faster feature delivery |
| Codebase Refactoring | Agents handle different parts of the codebase simultaneously | Reduced refactoring time |
| Adversarial Testing | One agent writes code, another tries to break it | Better code quality |
| Documentation | Separate agents for API docs, tutorials, and examples | Comprehensive docs faster |
For teams already using Claude Code heavily, this changes the math on what is worth automating.
1 Million Token Context Window
Opus 4.6 expands the context window from 200,000 tokens to 1 million tokens, a 5x increase. This is available in beta through the developer platform.
What 1 Million Tokens Looks Like
1 Million Token Capacity
├── ~750,000 words of text
├── ~3,000 pages of documents
├── ~50 average-sized codebases
├── ~15-20 full technical books
├── ~6 months of daily conversation history
└── An entire medium-sized application repositoryLong-Context Retrieval (MRCR v2)
The MRCR v2 benchmark with 8-needle retrieval shows how well models can find specific information buried in massive contexts. Opus 4.6 dominates this benchmark:
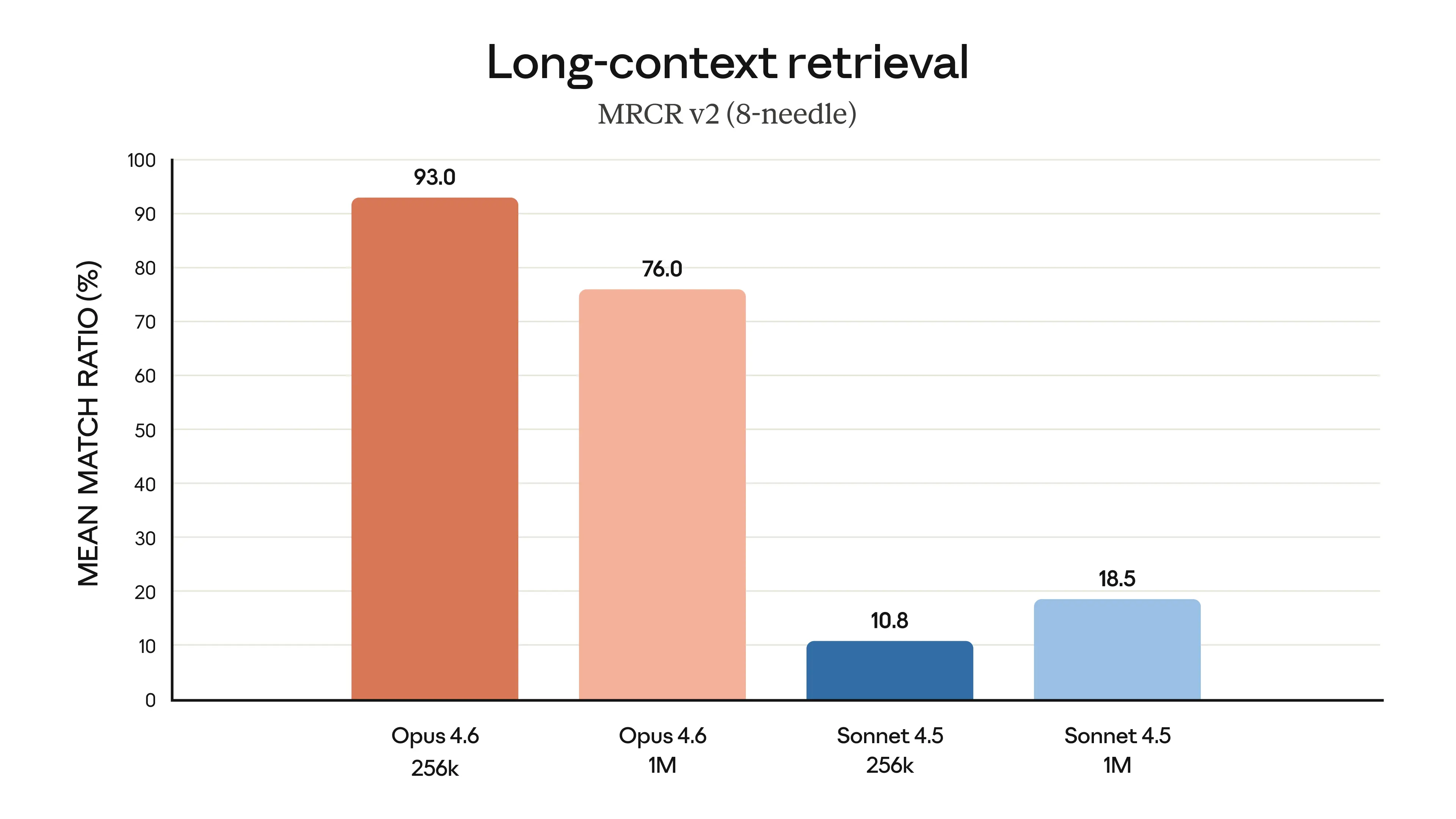 Opus 4.6 achieves 93.0% at 256K and 76.0% at 1M; Sonnet 4.5 manages only 10.8% and 18.5% respectively
Opus 4.6 achieves 93.0% at 256K and 76.0% at 1M; Sonnet 4.5 manages only 10.8% and 18.5% respectively
| Context Size | Opus 4.6 (256K) | Opus 4.6 (1M) | Sonnet 4.5 (256K) | Sonnet 4.5 (1M) |
|---|---|---|---|---|
| MRCR v2 (8-needle) | 93.0% | 76.0% | 10.8% | 18.5% |
Long-Context Reasoning (Graphwalks)
Beyond retrieval, Opus 4.6 shows strong reasoning over long contexts:
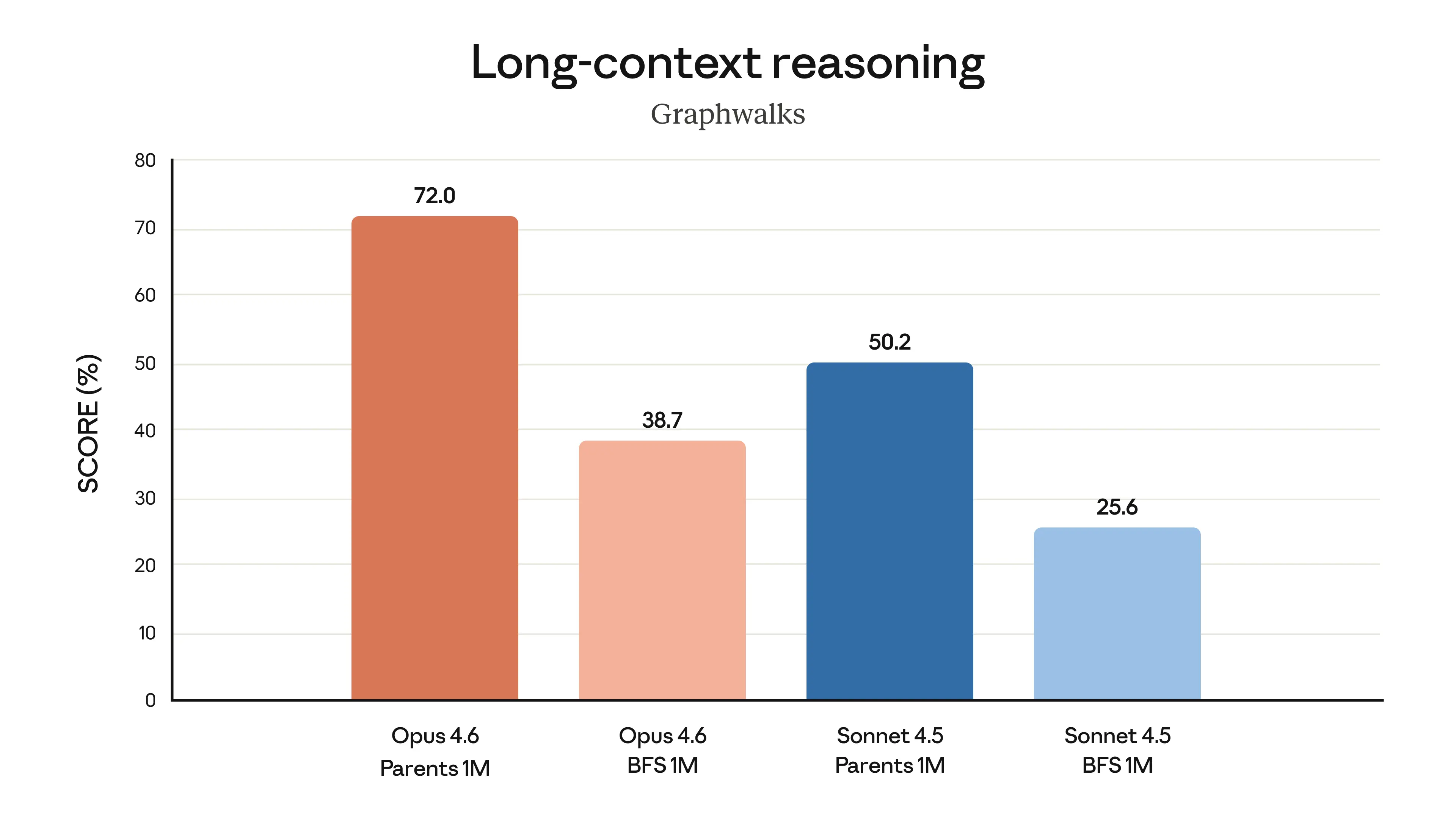 Opus 4.6 scores 72.0% on Parents 1M task vs Sonnet 4.5’s 50.2%
Opus 4.6 scores 72.0% on Parents 1M task vs Sonnet 4.5’s 50.2%
Opus 4.6 achieves 72.0% on the Graphwalks Parents 1M benchmark, compared to Sonnet 4.5’s 50.2%. On the harder BFS 1M task, Opus 4.6 reaches 38.7% versus Sonnet 4.5’s 25.6%.
Practical Impact for Developers
| Before (200K limit) | After (1M limit) |
|---|---|
| Carefully select which files to include | Feed entire repositories |
| Lose context mid-conversation | Maintain full project context |
| Split large tasks across sessions | Handle everything in one session |
| Summarize long documents | Process documents in full |
Adaptive Thinking and Effort Controls
Opus 4.6 introduces a new system for controlling how much the model “thinks” before responding.
Effort Levels Explained
| Level | Behavior | Best For | Latency |
|---|---|---|---|
| Low | Minimal thinking, quick responses | Simple queries, chat | Fastest |
| Medium | Moderate thinking when needed | General tasks | Fast |
| High (default) | Almost always thinks deeply | Complex reasoning | Moderate |
| Max | Maximum thinking on every request | Critical analysis | Slowest |
How Adaptive Thinking Works
Adaptive Thinking Flow
┌────────────────────────────────────────┐
│ Incoming Request │
└──────────────────┬─────────────────────┘
│
▼
┌────────────────────────────────────────┐
│ Evaluate Request Complexity │
│ │
│ • Simple factual query? │
│ • Multi-step reasoning needed? │
│ • Code generation required? │
│ • Analysis of multiple factors? │
└──────────────────┬─────────────────────┘
│
┌─────────┴─────────┐
│ │
Simple Task Complex Task
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ Skip or Light │ │ Deep Extended │
│ Thinking │ │ Thinking │
└─────────────────┘ └─────────────────┘This is especially powerful for agentic workflows where Claude needs to think between tool calls (interleaved thinking).
Comprehensive Benchmark Comparison
Here is the full official benchmark comparison from Anthropic, showing Opus 4.6 against all major competitors:
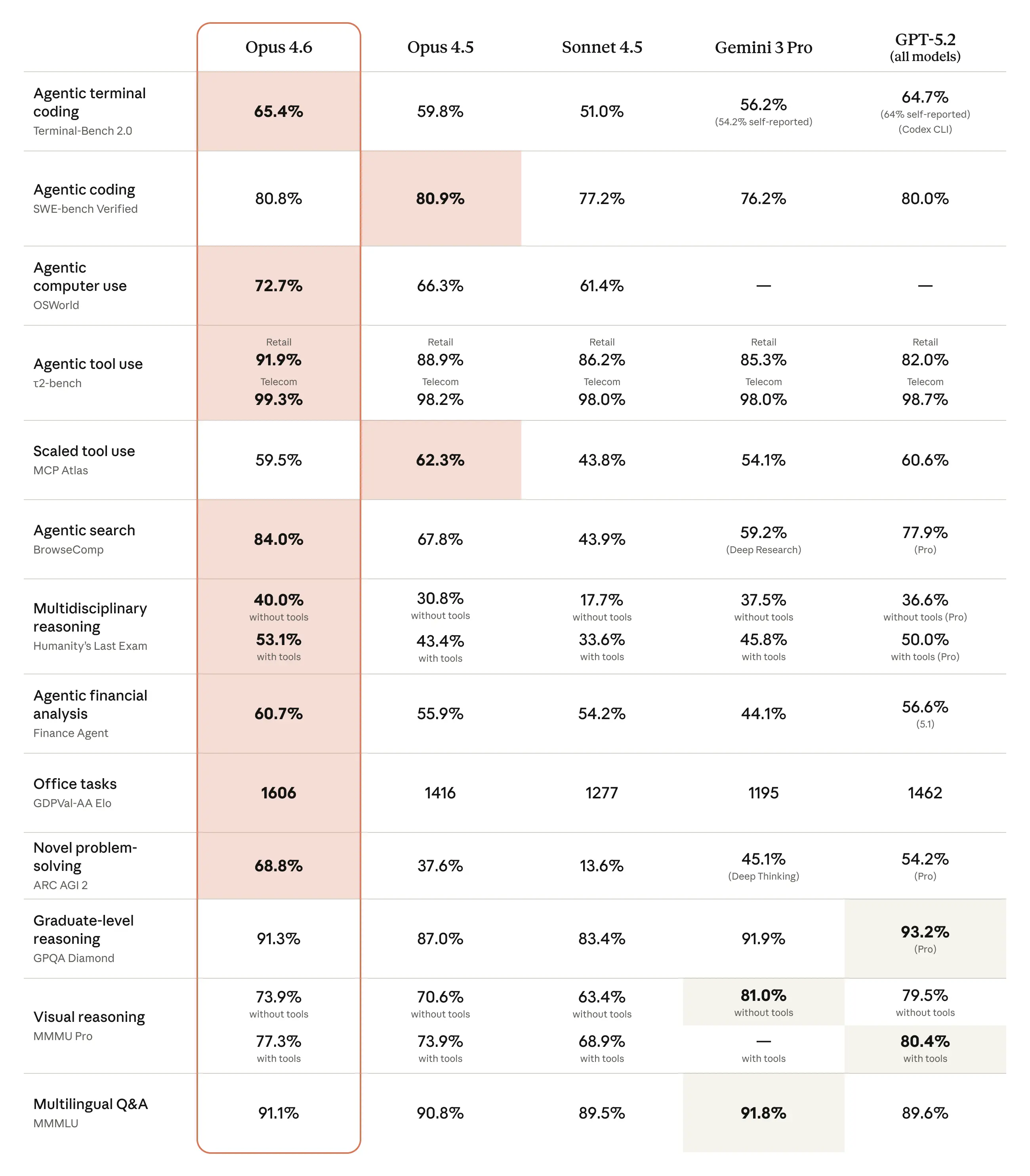 Official Anthropic benchmark results comparing Opus 4.6, Opus 4.5, Sonnet 4.5, Gemini 3 Pro, and GPT-5.2
Official Anthropic benchmark results comparing Opus 4.6, Opus 4.5, Sonnet 4.5, Gemini 3 Pro, and GPT-5.2
Key Benchmark Results
| Benchmark | Opus 4.6 | Opus 4.5 | Sonnet 4.5 | Gemini 3 Pro | GPT-5.2 |
|---|---|---|---|---|---|
| Agentic terminal coding (Terminal-Bench 2.0) | 65.4% | 59.8% | 51.0% | 56.2% | 64.7% |
| Agentic coding (SWE-bench Verified) | 80.8% | 80.9% | 77.2% | 76.2% | 80.0% |
| Agentic computer use (OSWorld) | 72.7% | 66.3% | 61.4% | — | — |
| Agentic search (BrowseComp) | 84.0% | 67.8% | 43.9% | 59.2% | 77.9% |
| Graduate-level reasoning (GPQA Diamond) | 91.3% | 87.0% | 83.4% | 91.9% | 93.2% |
| Novel problem-solving (ARC AGI 2) | 68.8% | 37.6% | 13.6% | 45.1% | 54.2% |
| Multilingual Q&A (MMLU) | 91.1% | 90.8% | 89.5% | 91.8% | 89.6% |
| Office tasks (GDPval-AA Elo) | 1606 | 1416 | 1277 | 1195 | 1462 |
Where Opus 4.6 Leads
Agentic search (BrowseComp) saw the largest improvement, from 67.8% to 84.0%, a +16.2 point jump that puts Opus 4.6 far ahead of all competitors.
Novel problem-solving (ARC AGI 2) nearly doubled from 37.6% to 68.8%, showing a massive leap in creative reasoning capability.
Knowledge work (GDPval-AA) measures performance on economically valuable tasks in banking and legal analysis. Opus 4.6 leads with an Elo score of 1606:
| Model | GDPval-AA Elo |
|---|---|
| Opus 4.6 | 1606 |
| GPT-5.2 | 1462 |
| Opus 4.5 | 1416 |
| Sonnet 4.5 | 1277 |
| Gemini 3 Pro | 1195 |
Long-Term Coherence (Vending-Bench 2)
This benchmark measures how well models maintain coherence over extended multi-step tasks. Opus 4.6 leads by a significant margin:
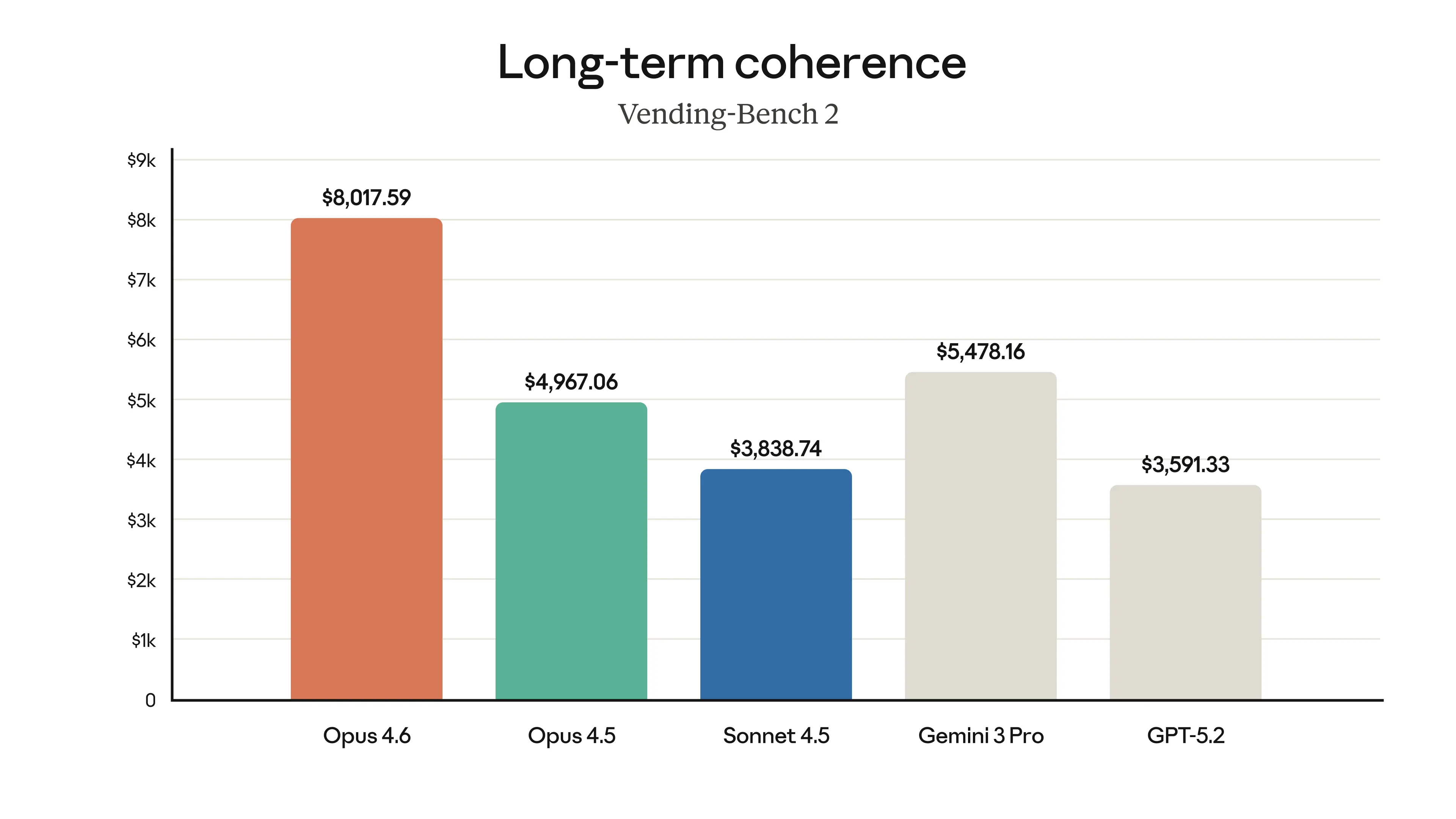 Opus 4.6 scores $8,017.59, nearly double Opus 4.5’s $4,967.06
Opus 4.6 scores $8,017.59, nearly double Opus 4.5’s $4,967.06
Opus 4.6’s score of $8,017.59 represents a 61% improvement over Opus 4.5 ($4,967.06) and a massive lead over Sonnet 4.5 ($3,838.74) and GPT-5.2 ($3,591.33).
Specialized Domain Benchmarks
Opus 4.6 shows strong gains across specialized domains.
Cybersecurity Vulnerability Reproduction (CyberGym)
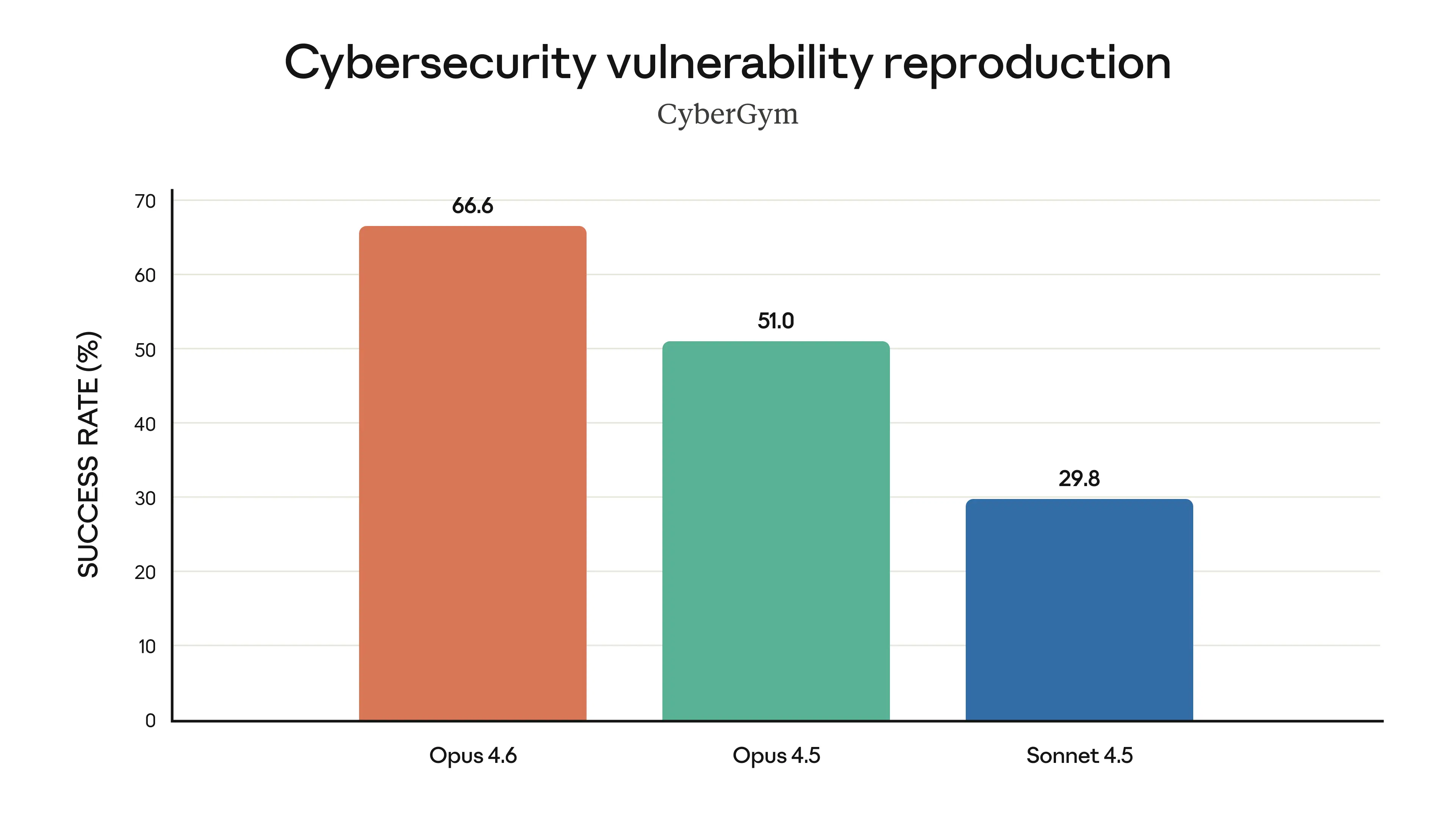 Opus 4.6 achieves 66.6% success rate, 30% higher than Opus 4.5’s 51.0%
Opus 4.6 achieves 66.6% success rate, 30% higher than Opus 4.5’s 51.0%
Software Failure Diagnosis (OpenRCA)
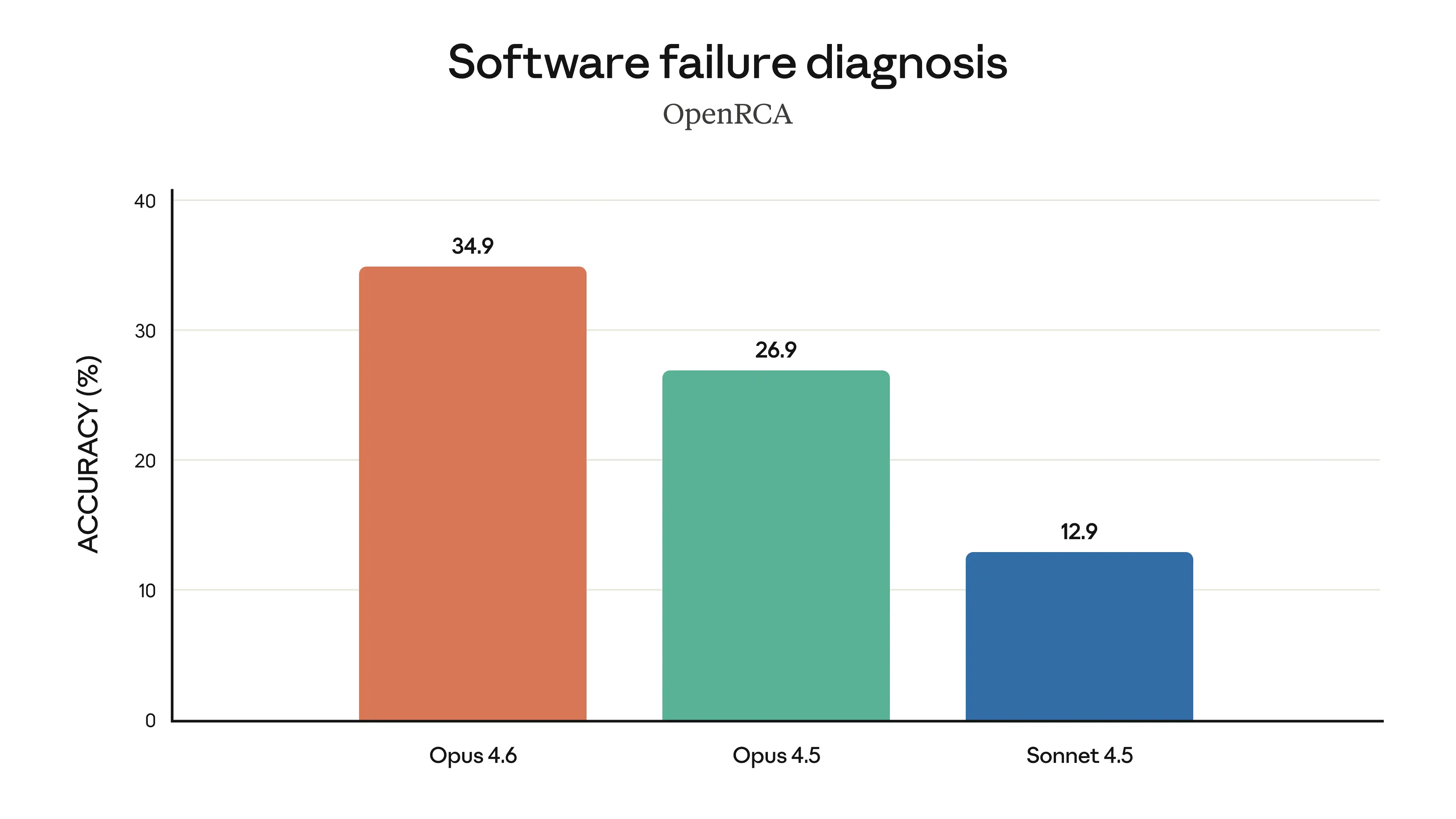 Opus 4.6 reaches 34.9% accuracy, up from 26.9% for Opus 4.5 and 12.9% for Sonnet 4.5
Opus 4.6 reaches 34.9% accuracy, up from 26.9% for Opus 4.5 and 12.9% for Sonnet 4.5
Multilingual Coding (SWE-bench Multilingual)
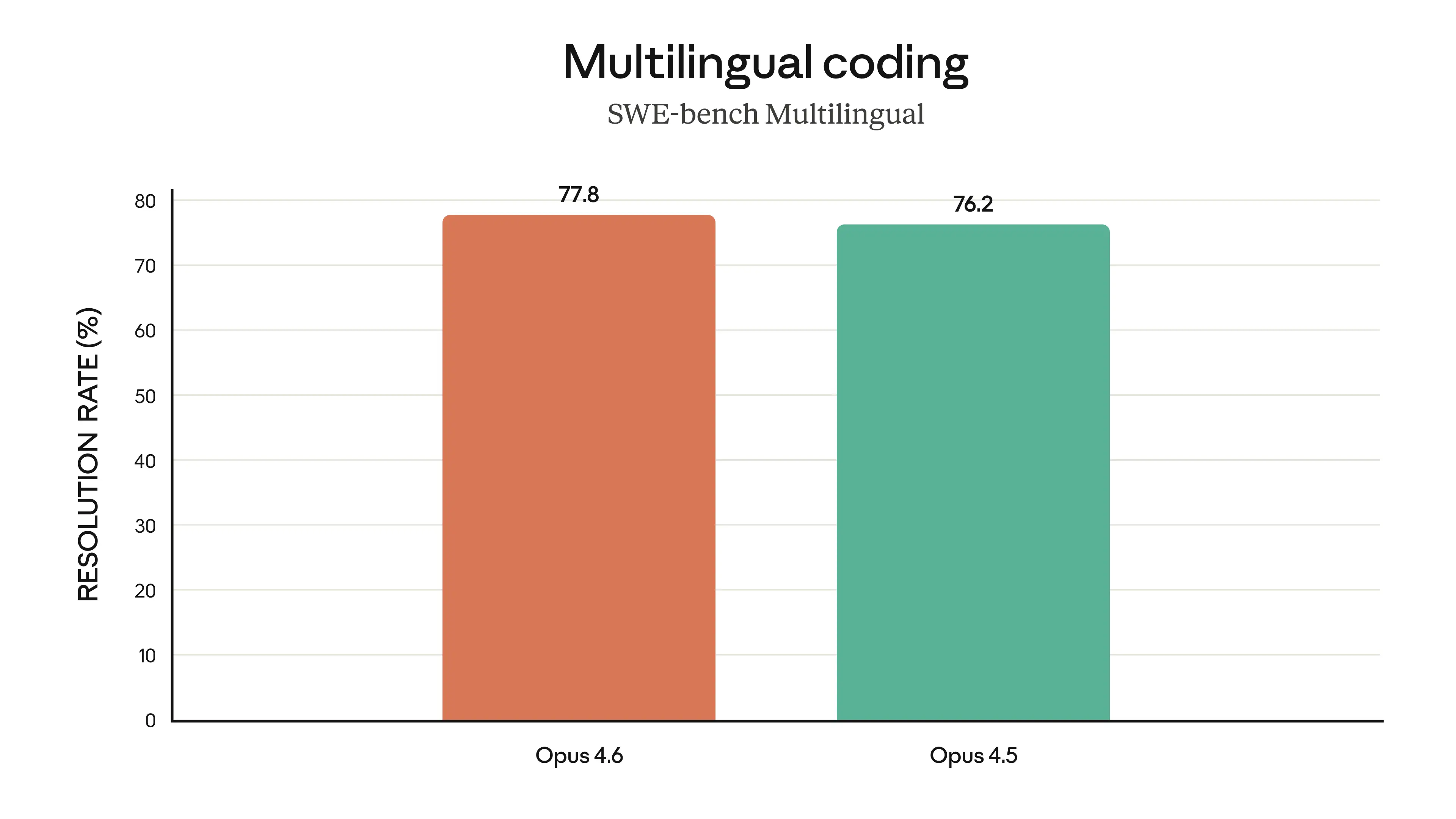 Opus 4.6 at 77.8% vs Opus 4.5 at 76.2% on multilingual code resolution
Opus 4.6 at 77.8% vs Opus 4.5 at 76.2% on multilingual code resolution
Computational Biology (BioPipelineBench)
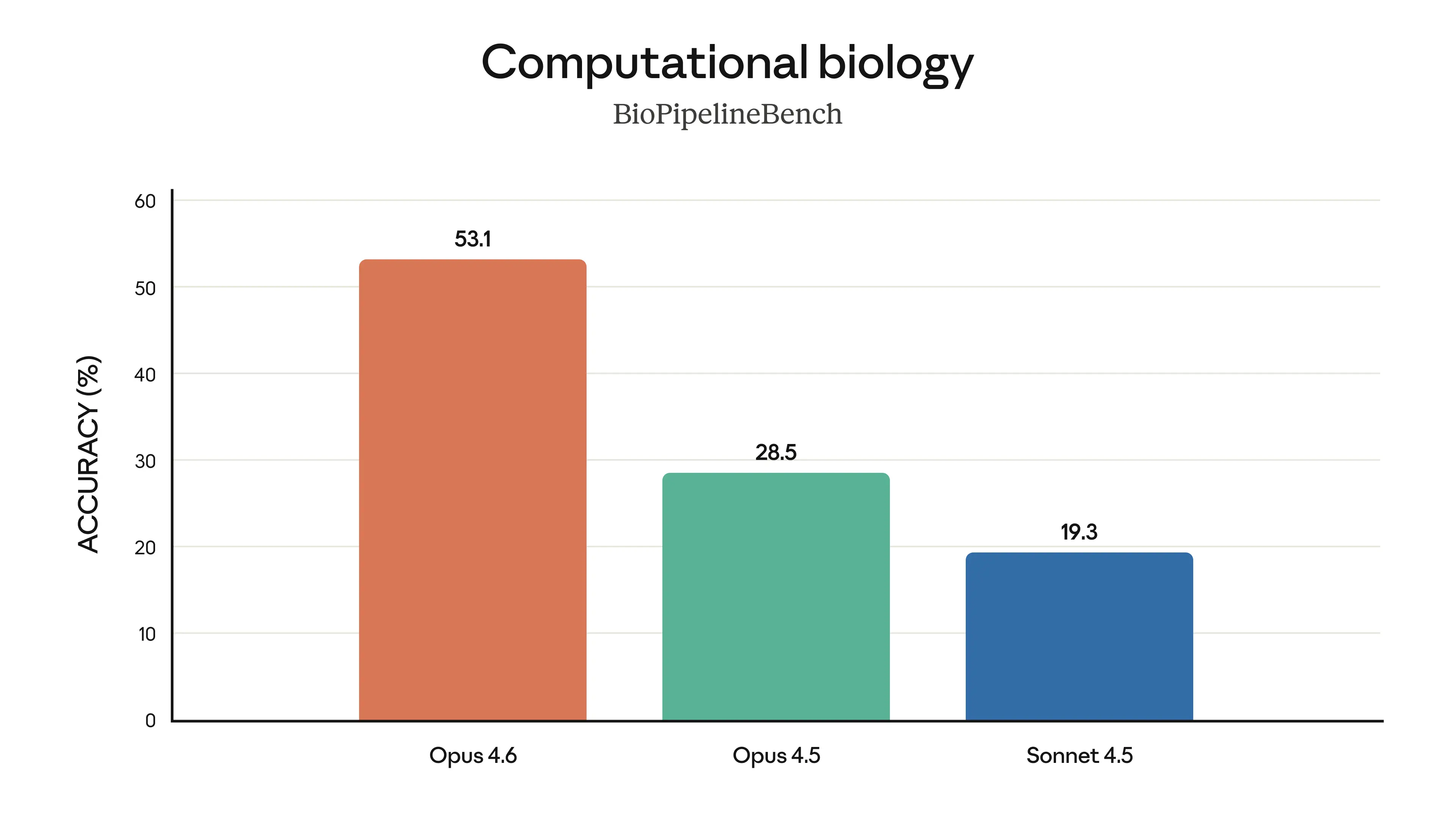 Opus 4.6 scores 53.1%, nearly double Opus 4.5’s 28.5%
Opus 4.6 scores 53.1%, nearly double Opus 4.5’s 28.5%
Where Competitors Lead
Opus 4.6 does not win every benchmark:
- GPQA Diamond: GPT-5.2 (Pro) leads at 93.2%, Gemini 3 Pro at 91.9%, Opus 4.6 at 91.3%
- Visual reasoning (MMMU Pro): Gemini 3 Pro leads at 81.0% without tools, GPT-5.2 at 80.4% with tools
- Scaled tool use (MCP Atlas): Opus 4.5 scores 62.3% vs Opus 4.6’s 59.5%
The competition is tight, and no single model dominates every category.
Safety and Alignment
Anthropic highlights significant progress in safety with Opus 4.6:
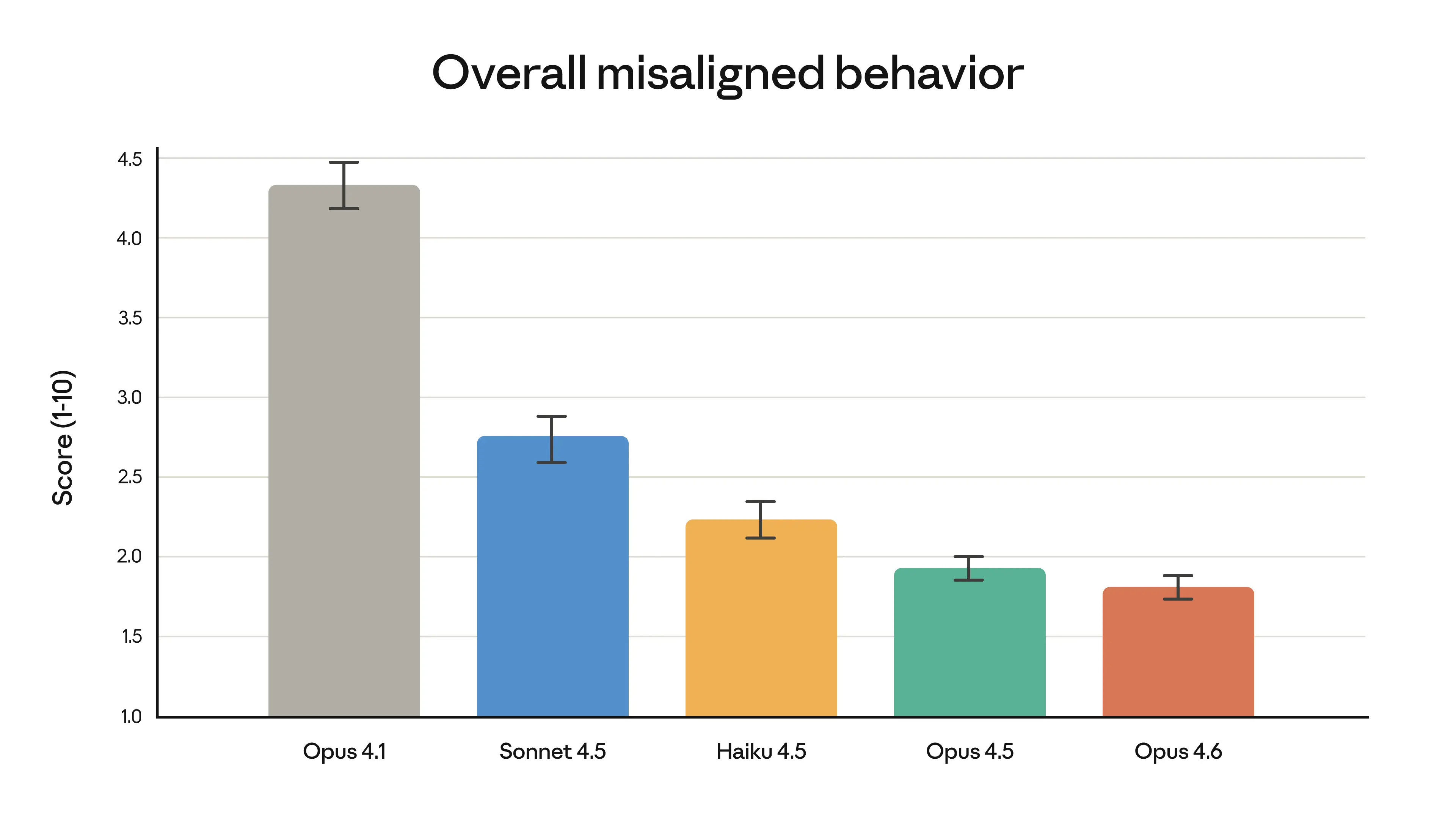 Lower scores are better. Opus 4.6 has the lowest misaligned behavior score at 1.8.
Lower scores are better. Opus 4.6 has the lowest misaligned behavior score at 1.8.
| Model | Misaligned Behavior Score |
|---|---|
| Opus 4.1 | 4.3 |
| Sonnet 4.5 | 2.7 |
| Haiku 4.5 | 2.2 |
| Opus 4.5 | 1.9 |
| Opus 4.6 | 1.8 |
Opus 4.6 achieves the lowest misalignment score across all Claude models, showing that capability improvements do not have to come at the expense of safety.
Pricing and Availability
API Pricing (Unchanged from Opus 4.5)
| Tier | Input Tokens | Output Tokens | Notes |
|---|---|---|---|
| Standard (≤200K context) | $5 / 1M | $25 / 1M | Most use cases |
| Premium (>200K context) | $10 / 1M | $37.50 / 1M | For 1M context beta |
| Prompt Caching | Up to 90% savings | — | Repeated prompts |
| Batch Processing | 50% discount | 50% discount | Non-real-time |
Claude Model Lineup Comparison
| Model | Best For | Input Price | Output Price | Context |
|---|---|---|---|---|
| Opus 4.6 | Complex reasoning, agents, enterprise | $5/1M | $25/1M | 1M |
| Sonnet 4.5 | Balanced performance, daily use | $3/1M | $15/1M | 200K |
| Haiku 4.5 | Speed, cost efficiency, high volume | $0.25/1M | $1.25/1M | 200K |
Platform Availability
| Platform | Status | Notes |
|---|---|---|
| Anthropic API | Available | Direct access |
| Claude.ai | Available | Consumer interface |
| AWS Bedrock | Available | Enterprise integration |
| Google Vertex AI | Available | GCP integration |
| Microsoft Azure Foundry | Available | Azure integration |
| Snowflake Cortex AI | Available | Data platform integration |
Microsoft Office Integration
Opus 4.6 expands Claude’s presence in Microsoft Office applications.
PowerPoint Integration (Research Preview)
PowerPoint Integration Capabilities
┌─────────────────────────────────────────────────────────────┐
│ │
│ INPUT OUTPUT │
│ ───── ────── │
│ • Existing slide layouts → • New slides matching │
│ • Brand fonts → your template style │
│ • Color schemes → • Edited slides preserving │
│ • Template styles → design elements │
│ • Content requirements → • Production-ready decks │
│ │
└─────────────────────────────────────────────────────────────┘This is not “generate slides from scratch”. It is “work within my existing brand guidelines and presentation style.”
Excel Integration (Updated)
- Now powered by Opus 4.6
- Supports native Excel operations (not just descriptions)
- Direct spreadsheet manipulation
- Formula generation and debugging
- Data analysis and visualization
The OpenAI Response
Twenty minutes after Anthropic announced Opus 4.6, OpenAI released GPT-5.3 Codex. The timing was not coincidental.
GPT-5.3 Codex Highlights
OpenAI clearly positioned GPT-5.3 Codex as a response to Claude’s dominance in agentic coding. The focus was on terminal operations and computer use, areas where GPT-5.2 already showed strength:
| Feature | GPT-5.2 Codex | GPT-5.3 Codex | Change |
|---|---|---|---|
| Terminal-Bench 2.0 | 64.0% | 77.3% | +13.3% |
| OSWorld | 71.2% | 78.4% | +7.2% |
| Focus | General coding | Terminal + computer use | Specialized |
The New AI Landscape
Model Specialization Map (February 2026)
┌─────────────────────────────────────────────────────────────┐
│ │
│ REASONING DEPTH │
│ ▲ │
│ │ │
│ Opus 4.6 ● │ │
│ (Complex reasoning, │ │
│ long context, │ ● Gemini 3 Pro │
│ enterprise) │ (Multimodal, balanced) │
│ │ │
│ │ │
│ ◄────────────────────────────────────────────────────────► │
│ TERMINAL/AGENT REASONING │
│ OPERATIONS │
│ │ │
│ ● GPT-5.3 Codex │ │
│ (Terminal tasks, │ │
│ computer use) │ │
│ │ │
│ ▼ │
│ SPEED/COST │
│ │
└─────────────────────────────────────────────────────────────┘What This Means for Developers
Decision Matrix: Which Model to Use
| Your Priority | Recommended Model | Why |
|---|---|---|
| Complex reasoning | Claude Opus 4.6 | Leads on BrowseComp, ARC AGI 2, knowledge work |
| Large codebase work | Claude Opus 4.6 | 1M context window with strong retrieval |
| Multi-agent systems | Claude Opus 4.6 | Native agent teams |
| Long-term coherence | Claude Opus 4.6 | Best on Vending-Bench 2 |
| Terminal automation | GPT-5.3 Codex | Best on Terminal-Bench |
| Computer use tasks | GPT-5.3 Codex | Best on OSWorld |
| Cost efficiency | Claude Haiku 4.5 | Lowest price, fast |
| Balanced daily use | Claude Sonnet 4.5 | Good all-around |
| Multimodal tasks | Gemini 3 Pro | Strong vision + text |
Migration Considerations
If you are currently using Opus 4.5:
| Aspect | Impact | Action Required |
|---|---|---|
| API compatibility | Fully compatible | None |
| Pricing | Unchanged | None |
| Context handling | May improve with 1M | Test with larger contexts |
| Response format | Same | None |
| Thinking patterns | New adaptive option | Consider enabling |
| Agent workflows | New teams feature | Explore for complex tasks |
The Bigger Picture
A year ago, AI coding assistants were fancy autocomplete. Today, they are building compilers from scratch through multi-agent coordination.
The Acceleration Timeline
AI Coding Capability Evolution
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
2024 Autocomplete, simple completions
│
▼
2025 H1 Full function generation, basic debugging
│
▼
2025 H2 Codebase-aware assistance, multi-file edits
│
▼
2026 Q1 Agent teams, 1M context, autonomous development
│
▼
2026 H2 ??? (Claude Sonnet 5 rumors, continued acceleration)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━The pace of improvement is not slowing down. Anthropic has already hinted at Claude Sonnet 5 coming soon. OpenAI clearly has more in the pipeline. Google’s Gemini team is not standing still.
For developers, this means the tools available to us are getting dramatically more capable every few months. The projects that seemed impossible last year are becoming routine. The workflows we are building today will seem primitive by year-end.
Whether that is exciting or terrifying probably depends on your perspective. Either way, Claude Opus 4.6 is another step into a future where AI is not just assisting development. It is actively participating in it.
Sources
- Introducing Claude Opus 4.6 - Anthropic
- Claude Opus 4.6 - Anthropic Product Page
- Anthropic releases Opus 4.6 with new ‘agent teams’ - TechCrunch
- Claude Opus 4.6 vs 4.5 Benchmarks - Vellum
- Claude Opus 4.6 for Developers - DEV Community
- Claude Opus 4.6: Features, Benchmarks, and Pricing Guide - Digital Applied
- Adaptive Thinking - Claude API Docs
- Claude Opus 4.6 now available in Amazon Bedrock - AWS
- Expanding Vertex AI with Claude Opus 4.6 - Google Cloud Blog
- AI War: 20 Minutes After Claude Opus 4.6, OpenAI Strikes Back - UC Strategies
- Anthropic launches Claude Opus 4.6 as AI moves toward ‘vibe working’ - CNBC
Sponsored
More from this category
More from AI Integration
 R.01
R.01 Document AI for Agencies: Extracting Structure from PDFs, Forms, and Contracts
 R.02
R.02 AI Video Generation in 2026: What Agencies Need to Know Before Pitching It to Clients
 R.03
R.03 Browser-Use Agents: Automating the Web When APIs Don't Exist
Sponsored
Discussion
Join the conversation.
Comments are powered by GitHub Discussions. Sign in with your GitHub account to leave a comment.
Sponsored